")
")
Podstawy sieci z Cisco IOS. Moduł 4: Syslog
Zadaniem protokołu Syslog jest dostarczenie powiadomienia o zdarzeniu. Został on opisany w dokumencie RFC5424. Syslog określa format wiadomości oraz sposób jej transmisji przez sieć, niemniej często kojarzony jest też z usługą systemu. Historia jego powstania prowadzi na Uniwersytet Kalifornijski w Berkeley i do systemów Unix z rodziny BSD (Berkeley Software Distribution).

W systemie Cisco IOS zdarzenia mogą być logowane do portu konsoli (domyślnie), linii wirtualnych VTY (trzeba włączać globalnie lub per linia), pamięci urządzenia (warto dostosować rozmiar bufora), zewnętrznego serwera Syslog (port 514/udp lub port 601/tcp lub port 6514/tcp z TLS) oraz stacji zarządzającej z użyciem pułapek SNMP (Simple Network Management Protocol).
RFC5424 opisujące protokół Syslog powstało w 2009 roku. Wcześniejsze RFC3164 opisujące zachowanie implementacji Syslog w BSD z 2001 roku miało charakter bardziej informacyjny i nie było standardem. O ile dokument z 2009 roku standaryzuje pewne obszary, to do tego czasu powstało wiele nieco różniących się formatów zapisu informacji o zdarzeniu czy implementacji tego protokołu. Jest to do dziś bolączką wielu rozwiązań klasy SIEM (Security Information and Event Management) czy może bardziej osób, zajmujących się ich wdrażaniem. Niestety, żaden standard nie zmieni tego, co powstało przed nim.
My ograniczymy się w tym module do formatu stosowanego w Cisco IOS. Informacja o zdarzeniu składa się z kilku elementów. Numer sekwencyjny i znacznik czasowy jest wartością opcjonalną, niemniej w środowisku produkcyjnym powinien być stosowany. Dalsza część wiadomości może posiadać jeden z dwóch formatów. Przykład obu można zobaczyć na powyższym slajdzie.
- Obiekt (ang. facility) powiązany z komunikatem może zostać wskazany wprost, z użyciem nazw, jak to widać w pierwszym przykładzie. Zaraz za nim, w nawiasach okrągłych - "()" - zostaje określony poziom powagi (ang. severity) czy też ważności tego zdarzenia, a za nim znajduje się już właściwa, zrozumiała dla administratora treść komunikatu zdarzenia.
- Stosowane są też komunikaty zawierające skrótowe nazwy w formie mnemicznej (ang. mnemonic). W takim przypadku nazwa obiektu jest odseparowana od ważności zdarzenia i zapisu mnemicznego z użyciem pauz "-". Zastosowanie mnemoników ułatwia zliczanie i filtrowanie zdarzeń. Na końcu znajduje się właściwa treść komunikatu.
Im niższa numerycznie wartość powagi (ang. severity), tym bardziej krytyczne zdarzenie. Wartość najbardziej krytyczna to "0" i oznacza "Emergency". Jeżeli widzimy komunikat o poziomie powagi "0" oraz "1" - "Alert", "2" - "Critical" lub "3" - "Error", to trzeba się nim zająć w trybie pilnym. Im wyższy numerycznie poziom powagi, tym mniej krytyczny komunikat. Zatem komunikaty o wartości "4" - "Warning" i "5" - "Notice" mają charakter bardziej ostrzegawczy. Natomiast komunikaty czysto informacyjne stosują wartość "6" - "Informational". Zdarzenia debugu generowane są z wartością "7" - "Debug".
Usługa logowania jest domyślnie włączona. Można ją wyłączyć z użyciem polecenie trybu konfiguracji globalnej "no logging on".

Aktualną konfigurację usługi logowanych zdarzeń zweryfikować można z użyciem polecenie trybu EXEC: "show logging". Warto zwrócić uwagę na pierwszy wiersz, gdzie widać czy usługa logowania jest aktywna. Niżej znajdują się trzy obszary, oznaczone kolejno z użyciem niebieskawego, zielonawego i czerwonawego tła. Odnoszą się one kolejno, do logowania zdarzeń na konsolę, terminale VTY, na których aktywowany został monitor oraz do lokalnego bufora. Zawartość bufora ze zdarzeniami widoczna jest na samym dole zrzutu poleceń, na czerwonawym tle. Rozmiar bufora widać na fioletowawym tle.
Aby wyczyścić zawartość bufora należy posłużyć się poleceniem trybu EXEC: "clear logging".
Jeżeli nie korzystamy z zewnętrznego serwera czy kolektora Syslog, warto zwiększyć domyślny rozmiar bufora. Dzięki temu potrzebne do diagnozy informacje nie będą znikały z urządzenia zbyt szybko. Zawartość lokalnego bufora jest czyszczona w trakcie restartu urządzenia oraz kiedy dochodzi do jego przepełnienia. W przypadku przepełnienia, usuwane są najstarsze zdarzenia. Rozmiar bufora można ustawić z użyciem polecenia trybu konfiguracji globalnej: "logging buffered". Po rozmiarze bufora (w bajtach) można także określić poziom zdarzeń. Domyślnie do bufora logowane są zdarzenia tylko do poziomu "Informational". Istnieje również możliwość dezaktywacji bufora. Służy do tego polecenie trybu konfiguracji globalnej: "no logging buffered".
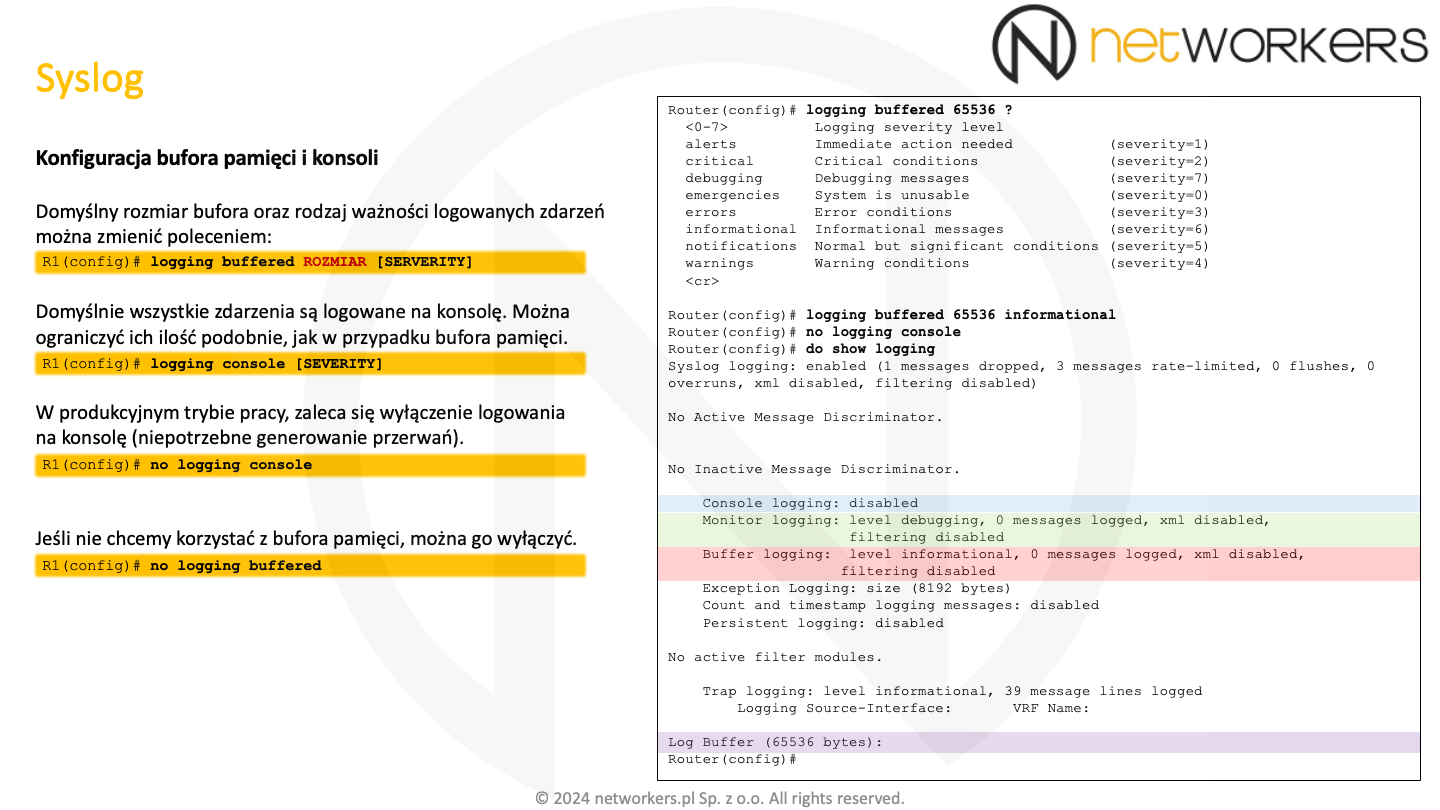
Domyślnie na konsolę logowane są wszystkie zdarzenia (do poziomu "Debug"). Z użyciem polecenia "logging console" możemy to zmienić. Natomiast w środowisku produkcyjnym, często całkiem wyłącza się logowanie zdarzeń do portu konsoli. Ma to uzasadnienie wydajnościowe. Zwykle już po wdrożeniu urządzenia nikt nie analizuje zdarzeń na konsoli, więc nie ma sensu by wyświetlające się tam zdarzenia generowały niepotrzebne przerwania (port konsoli pracuję z dość wolną prędkością). Jeżeli będzie to w przyszłości potrzebne, to na czas diagnozy bardzo łatwo da się to aktywować ponownie.
Kiedy zalogujemy się do linii wirtualnej VTY (terminal), domyślnie nie będą pokazywać się żadne zdarzenia. O ile można wtedy wyświetlić zawartość bufora, to istnieje też możliwość aktywowania wyświetlania zdarzeń na terminalu VTY. Służy do tego polecenie trybu EXEC: "terminal monitor". Aby ponownie wyłączyć logowanie tych zdarzeń, należy użyć polecenia: "terminal no monitor". Warto zwrócić uwagę, że "no" nie jest umiejscowione tutaj na początku polecenia. Po włączeniu monitorowania na terminalu, w wyniku polecenia: "show logging" pojawi się dodatkowa informacja, widoczna na slajdzie poniżej w czerwonym obramowaniu.
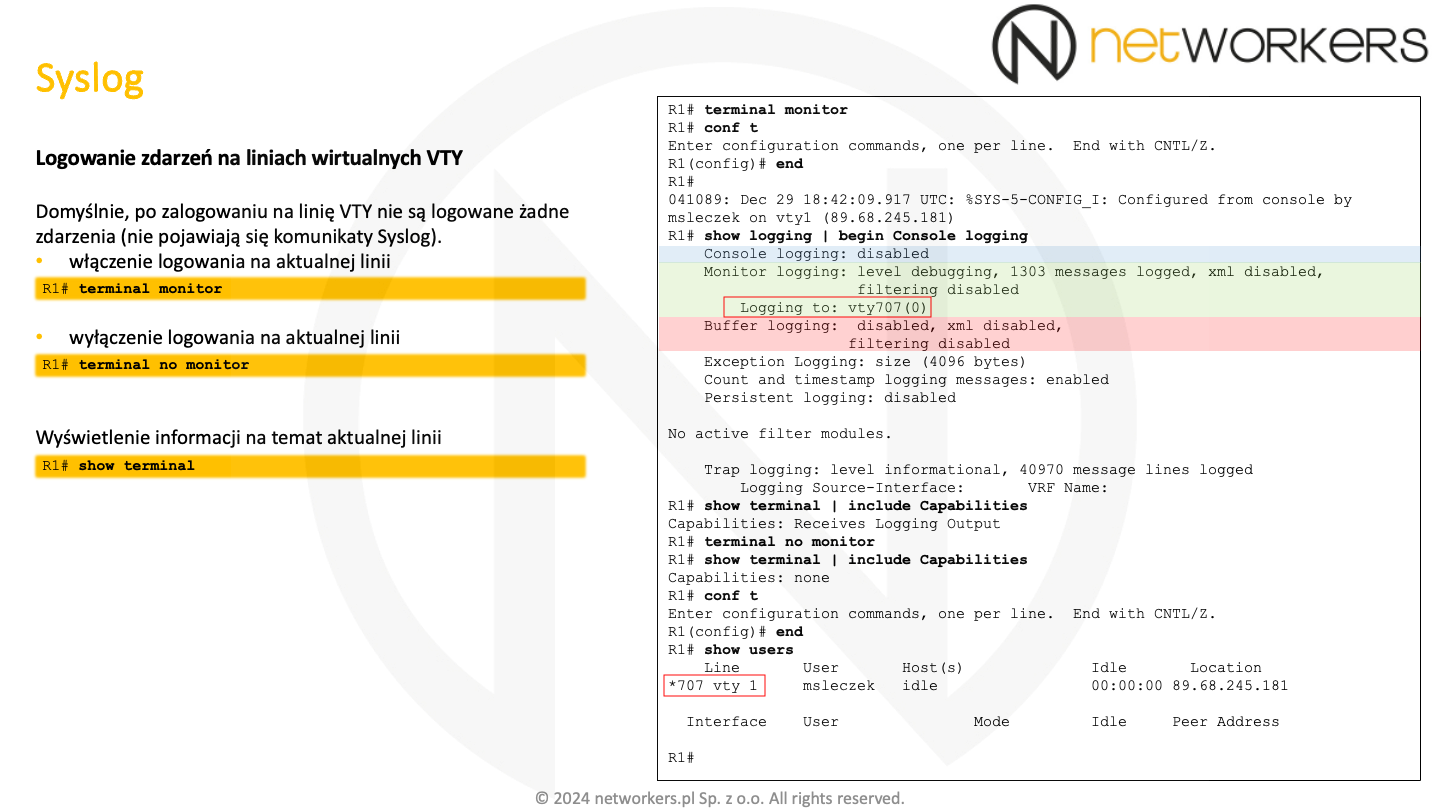
To domyślne zachowanie jest porządane. Gdyby ktoś włączył bardzo gadatliwy debug, to moglibyśmy nie być w stanie za wiele zrobić. A już na pewno, nie byłoby to wygodne i szybkie. A tak, zawsze można otworzyć kolejną sesję SSH, gdzie nic się nie pojawia i nie przeszkadza, a następnie zająć się diagnozą, konfiguracją czy też wyłączeniem problematycznego debugu. Informacje o aktualnie używanym terminalu można zweryfikować z użyciem polecenia trybu EXEC: "show terminal".
Zdarza się, że w ramach jednej infrastruktury działają urządzenia z różnej epoki oraz z różną wersją oprogramowania. W takich miejscach szczególnie warto przyjrzeć się logowanym zdarzeniom, zwracając uwagę na zawarte w nich znaczniki czasowe. Istotne jest to, by znaczniki te były spójne i zawierały wszystkie niezbędne informacje.
Uspójnić je można z użyciem polecenia trybu konfiguracji globalnej: "service timestamps". Możemy zdefiniować inne wymagania dla informacji generowanych przez debug (parametr "debug") i inne dla pozostałych zdarzeń (parametr "log"). W obu przypadkach trzeba najpierw określić, czy znacznik czasowy ma bazować na aktualnej dacie i godzinie (parametr "datetime"), czy czasie liczonym od włączenia urządzenia (parametr "uptime"). W przypadku debugu, często przydają się bardziej szczegółowe informacje czasowe i dodaje się parametr "msec". Syslog przesyła czas w formie tekstu (ang. string), który może być czasem lokalnym (parametr "localtime") lub czasem UTC (gdy nie podamy parametru "localtime"). Na pewno dobrym pomysłem będzie dodanie informacji o strefie czasowej. W przypadku zdarzeń, które nie powstają w wyniku debugowania, użyteczne jest też dodanie roku (parametr "year"). Bywa, że takie zdarzenia są składowane w okresie dłuższym niż rok.

Jeżeli chodzi o znaczniki czasowe, to bardzo istotne jest zadbanie o synchronizację czasu, do czego służy protokół NTP. Na początku znacznika czasowego, w zdarzeniu Syslog może znajdować się:
- [nic] – zegar został ustawiony ręcznie lub jest w synchronizacji z serwerem NTP,
- * [gwiazdka] – zegar nie został ustawiony lub nie jest w synchronizacji z serwerem NTP,
- . [kropka] – zegar był zsynchronizowany, ale utracił kontakt z serwerem NTP.
Dobrą praktyką jest także dodawanie numerów sekwencyjnych do każdego zdarzenia, generowanego przez urządzenie. Służy do tego polecenie trybu konfiguracji globalnej: "service sequence-numbers". Pozwoli to kolektorowi czy serwerowi Syslog wyłapać sytuacje, w których doszło do zgubienia zdarzeń (np. awaria w sieci) czy też ich usunięcia (np. próba zatuszowania jakiś zdarzeń).
Gdy brakuje miejsca, usuwane są z bufora najstarsze zdarzenia. Aby zachować informacje o rodzaju i ilości historycznych zdarzeń, warto uruchomić usługę ich zliczania. Dokonać tego można z użyciem polecenia trybu konfiguracji globalnej: "logging count". Usługa ta korzysta z zapisu mnemonicznego ("Message Name" w tabeli poniżej) dla generowanych przez dany obiekt (kolumna "Facility") zdarzeń. Ułatwia to zachowanie zwartej i przejrzystej formy. Dla każdego mnemonika można zobaczyć poziom ważności (kolumna "Sev" od "Severity"), ilość wystąpień (kolumna "Occur") oraz to, kiedy zostało ono osatni raz wygenerowane (kolumna "Last Time"). Dostęp do tych informacji można uzyskać z użyciem polecenia trybu EXEC: "show logging count".

Zestawiane przez tą usługę informacje nie są usuwane nawet po ręcznym wyczyszczeniu lokalnego bufora pamięci Syslog. Aby je wyzerować, należy wyłączyć i włączyć ponownie tą usługę. Usługa ta jest bardzo użyteczna, nawet kiedy korzystamy z zewnętrznego kolektora czy serwera Syslog. A to dlatego, że w łatwy i szybki sposób możemy ocenić stan lokalnego urządzenia.
W środowisku produkcyjnym warto też wskazać zewnętrzny kolektor czy serwer Syslog. Służy do tego polecenie trybu konfiguracji globalnej "logging host". Warto pamiętać, że oprócz zdarzenia zostanie zalogowany jego źródłowy adres IP. Stąd, jeżeli urządzenie posiada wiele interfejsów, dobrą praktyką jest wybranie dla usługi Syslog jednego z nich (najczęściej jest to loopback). Aby tego dokonać, należy posłużyć się poleceniem trybu konfiguracji globalnej: "logging source-interface".

Warto też określić, do jakiego poziomu zdarzenia mają być wysyłane do zewnętrznego kolektora Syslog. Służy do tego polecenie trybu konfiguracji globalnej: "logging trap", po którym należy wskazać poziom z użyciem cyfry lub nazwy. Warto tutaj pamiętać, że wyższa wartość "severity level" zawiera w sobie także te niższe.
Domyślnie komunikaty wysyłane do zewnętrznego serwera Syslog będą identyfikowane z "Facility" local7. Wartość ta wskazuje na obiekt generujący komunikat i można ją zmienić z użyciem polecenia trybu konfiguracji globalnej: "logging facility". Wartość tą można wykorzystać po stronie kolektora Syslog do segregowania czy też wysyłania wiadomości do różnych plików.
Przed kolejną porcją wiedzy zachęcamy do przećwiczenia i utrwalenia tej poznanej tutaj. Skorzystaj z naszych ćwiczeń!