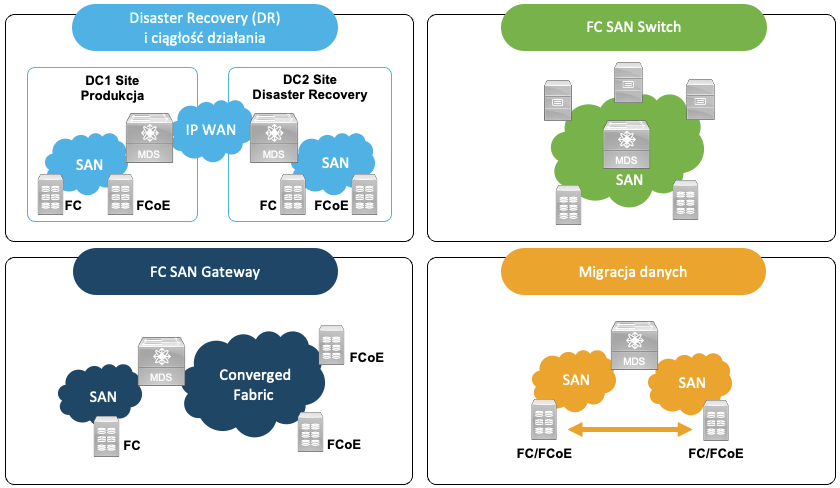
")
")
Podstawy sieci z Cisco IOS. Moduł 4: NetFlow
NetFlow jest zarówno protokołem, jak i usługą czy też funkcjonalnością dostępną w Cisco IOS. NetFlow jest protokołem służącym do eksportu informacji na temat ruchu, jaki miał miejsce w sieci. Informacje te nazywane są przepływami (ang. flows). Z usługi NetFlow głównie korzysta się tam, gdzie pojawia się potrzeba gromadzenia informacji o wymienianym ruchu. Poza aspektami prawnymi, które mogą narzucać przetrzymywanie takich informacji, są one często gromadzone z innych powodów. Pozwalają wizualizować aktualny i historyczny przebieg ruchu w sieci, dzięki czemu są dobrą podstawą planowania jej przyszłych zmian oraz obrazowania wpływu tych zmian na jej działanie. Dają możliwość monitorowania działających aplikacji i usług oraz analizę zachodzących w sieci zdarzeń i anomalii. Dzięki nim, łatwiej możemy wskazać źródło ataku lub niepowołanego incydentu. Dane te również są używane pomiędzy różnymi organizacjami w celach marketingowych lub rozliczeniowych.
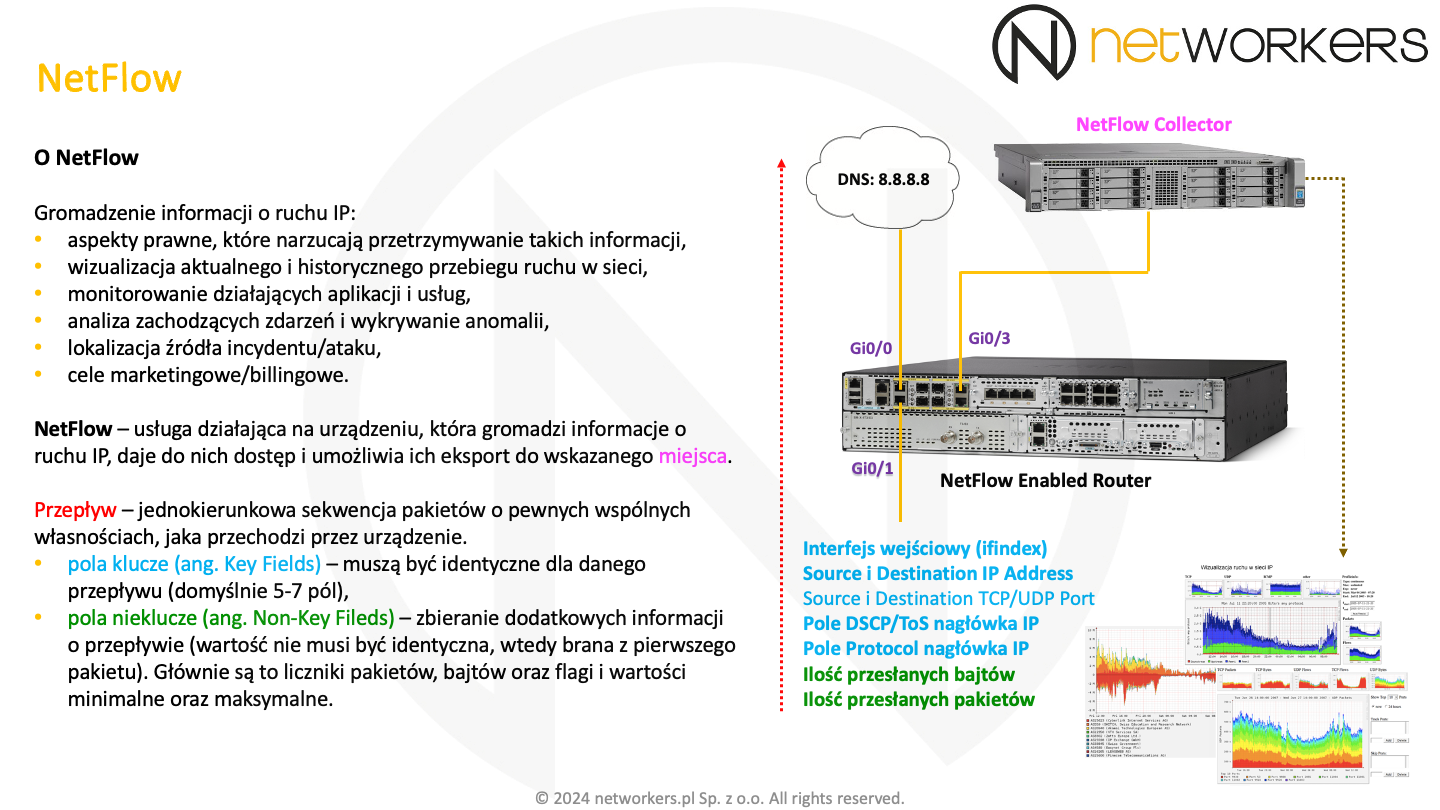
NetFlow umożliwia dostęp do informacji o przesyłanym w sieci ruchu oraz eksport tych informacji do wskazanego miejsca, nazywanego kolektorem (ang. collector). Informacje te gromadzone są w formie przepływów (ang. flow).
Przepływ, to jednokierunkowa sekwencja pakietów o pewnych wspólnych właściwościach. Wspólne właściwości określone są przez pola klucze lub inaczej pola kluczowe (ang. key fields). Dla każdego przepływu istnieje możliwość zbierania dodatkowych, odnoszących się do niego informacji. Są one przetrzymywane w polach nie-kluczach lub inaczej polach niekluczowych (ang. non-key fields). Jako, że wartość pól niekluczowych nie musi być identyczna, to jest ona brana z pierwszego pakietu składającego się na dany przepływ. Nie dotyczy to pól liczników, flag, wartości minimalnych i maksymalnych, które też należą do pól niekluczowych.
Początkowo, przepływy można było zbierać tylko na wejściu interfejsu (ang. ingress), obsługiwany był tylko protokół IP w wersji 4, a pola klucze były na stałe zdefiniowane i niezmienne. Podstawowe parametry pełniące funkcję pól kluczowych:
- interfejs wejściowy (SNMP ifIndex),
- pola Source i Destination Address w nagłówku protokołu IPv4,
- pole DSCP (Differentiated Services Code Point), dawniej ToS (Type of Service) w nagłówku IPv4,
- pole Protocol w nagłówku IPv4,
- pola Source i Destination Port w nagłówku protokołu TCP/UDP.
Oczywiście, ostatnie dwa pola klucze dotyczą tylko ruchu TCP/UDP, stąd mamy od 5 do 7 parametrów kluczowych.
Powyżej, w prawym dolnym rogu slajdu zostało pokazane kilka zrzutów graficznych z kolektora NetFlow. Widać na nich przykład wizualizacji ruchu. W łatwy sposób można zaznaczyć interesujący nas fragment wykresu, by zobaczyć składający się na niego ruch. Dzięki temu nie tylko wiemy ile ruchu pojawiło się w naszej sieci, ale też co to był za ruch.
W danych eksportowanych o przepływach zawarta jest informacja na temat interfejsu wejściowego i wyjściowego. Jest to tak zwany ifIndex (Interface Index), którym identyfikowany jest każdy interfejs w systemie (fizyczny i logiczny). ifIndex jest obiektem drzewa MIB-II (Management Information Base) protokołu SNMP (Simple Network Management Protocol). Wartość ta została początkowo zdefiniowana w RFC1213. Zgodnie z nim, każdemu interfejsowi jest przyznawana unikalna wartość z przedziału od 1 do ifNumber, gdzie ifNumber określał aktualną ilość interfejsów w systemie. Wartość ta pozostaje bez zmian do czasu kolejnej reinicjalizacji systemu. O ile interfejsy fizyczne są wbudowane lub nieczęsto zmieniane, to pojawia się coraz więcej zastosowań interfejsów logicznych. Sprawia to, iż ilość ich nie tylko rośnie, ale także dynamicznie się zmienia. Przydział numerów ifIndex zgodnie z RFC1213 stał się zatem problematyczny, gdyż nowy interfejs mógł odziedziczyć numer poprzedniego, co prowadziło do złej interpretacji danych przez systemy zarządzające i monitorujące sieć. Aby wyjść temu problemowi na przeciw, powstał dokument RFC2863, który porzucił wymóg zamkniętego przedziału od 1 do ifNumber. W zależności od platformy, numery ifIndex niektórych interfejsów mogą być zawsze stałe, a na niektórych po reinicjalizacji systemu mogą ulegać zmianie. Stąd wcześniej warto się upewnić co do tego zachowania na wykorzystywanych przez nas platformach. Aby wymusić zachowywanie stałych numerów dla posiadanych przez urządzenie interfejsów, należy skorzystać z polecenia trybu konfiguracji globalnej: "snmp-server ifindex persist". W wyniku tego polecenia numery interfejsów będą zapisywane w pliku "nvram:/ifIndex-table", dzięki czemu będą zawsze takie same.
Na slajdzie poniżej został zobrazowany przebieg czy może bardziej cykl życia przpływów obsługiwanych przez NetFlow.
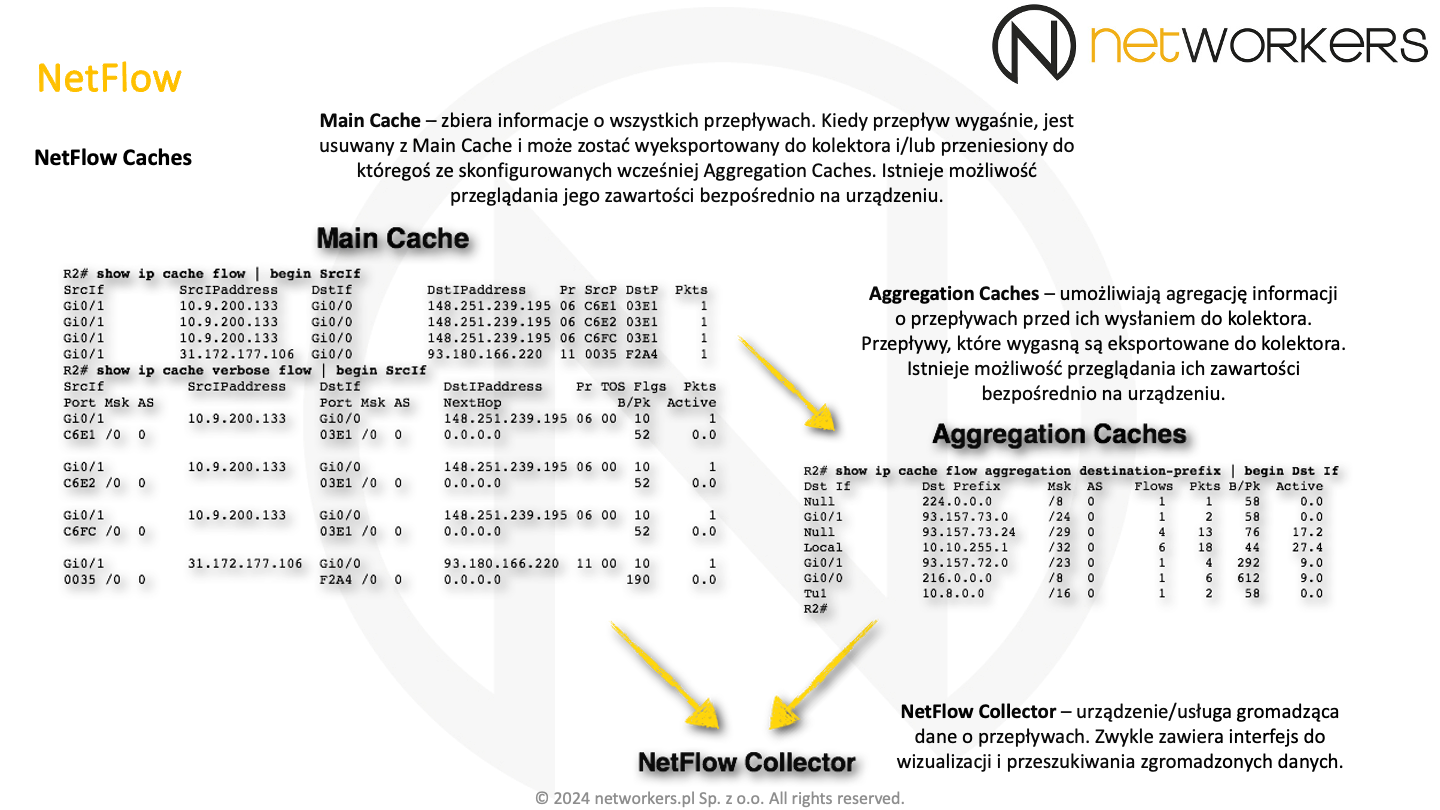
Informacja o aktywnych przepływach zbierane są w pamięci "Main Cache". Domyślnie, kiedy przepływ wygaśnie, jest usuwany z "Main Cache" i może zostać wyeksportowany do zewnętrznego kolektora lub przeniesiony do któregoś z "Aggregation Caches". Wykorzystanie "Aggregation Caches" wymaga ich wcześniejszego skonfigurowania. Bez tego dane o przepływach są po prostu usuwane z "Main Cache" lub eksportowane, jeśli również zostało to wcześniej odpowiednio skonfigurowane.
Tradictional NetFlow, którym się tutaj zajmujemy, nie obsługuje IPv6. Nie wykrywa też UDP-Lite, które stosowane jest tam, gdzie w przypadku IPv6 chcemy uniknąć wyliczania sumy kontrolnej dla każdego datagramu (np. w celu zwiększenia wydajności tuneli CAPWAP działających po IPv6). Oznacza to, że dla ruchu UDP-Lite rozpatrywane będzie tylko 5 pól kluczowych. Wsparcie dla IPv6 pojawiło się wraz z wprowadzeniem Flexible NetFlow. Tradictional NetFlow jest o wiele prostszy w konfiguracji i działa też na starszych urządzeniach. Dlatego właśnie on został wybrany i dołączony do tego szolenia wprowadzającego z podstaw sieci.

NetFlow składa się z dwóch komponentów. Jeden zajmuje się obsługą przepływów w lokalnej pamięci urządzenia, a drugi ich eksportem do kolektora. Rodzaj i ilość danych eksportowanych do kolektora zależy od wybranej wersji eksportu danych. Należy pamiętać, że niekoniecznie wszystkie informacje, jaki można zobaczyć w lokalnej pamięci urządzenia będą eksportowane i niekoniecznie wszystkie będą wspierane przez kolektor. Dostępnych jest kilka wersji formatu eksportu danych NetFlow.
Oryginalny format eksportu (wersja 1 czy też NetFlow v1), obsługiwany jest od samego początku protokołu NetFlow. Dostępny od wersji 11.0 oprogramowania Cisco IOS. Obecnie nie jest stosowany, za wyjątkiem potrzeby kooperacji z kolektorami nie wspierającymi wyższych wersji. Obsługuje on tylko protokół IPv4 i eksport danych tylko z "Main Cache". W każdym pakiecie może przenosić do 24 przepływów. Format ten zakłada, że wszystkie informacje o przepływach są zbierane tylko na wejściu interfejsu (brak pola wskazującego kierunek przepływu). Do kolektora eksportowane są tylko podstawowe informacje na temat każdego z przepływów, którymi są (pola klucze zostały pogrubione, przy czym w wersji 9 może być nim też interfejs wyjściowy):
- interfejs wejściowy i wyjściowy (SNMP ifIndex),
- pola Source i Destination Address w nagłówku protokołu IPv4,
- pole DSCP (Differentiated Services Code Point), dawniej ToS (Type of Service) w nagłówku IPv4,
- pole Protocol w nagłówku IPv4,
- pola Source i Destination Port w nagłówku protokołu TCP/UDP,
- zbiorcze (OR) flagi dla protokołu TCP,
- adres IP urządzenia następnego przeskoku,
- łączna ilość przesłanych pakietów,
- łączna ilość przesłanych bajtów,
- czas trwania (rozpoczęcie i zakończenie).
Wersja 5 (NetFlow v5) eksportuje dodatkowo informacje na temat BGP ASN (AS number), masce prefiksu IP oraz dodała numer sekwencyjny, który rośnie per każdy przenoszony przepływ. O ile bywa nadal stosowana, to staje się coraz mniej popularna. Dzięki dodaniu numeru sekwencyjnego, kolektor jest w stanie wykryć brakujące przepływy, które mogły do niego nie dotrzeć. Obsługuje tylko protokół IPv4 i eksport danych z "Main Cache". W każdym pakiecie może przenosić do 30 przepływów. Format ten zakłada, że wszystkie informacje o przepływach są zbierane tylko na wejściu interfejsu. Wysyłanie danych o przepływach realizowane jest z użyciem protokołu UDP, czyli zawodnie. Wprowadzenie od wersji 5 numerów sekwencyjny, nie gwarantuje nam co prawda retransmisji tych informacji, ale daje możliwość wykrycia potencjalnych problemów. Ich przykładem mogą być problemy z pamięcią lub zbyt duże obciążenie urządzeń (kolektora, urządzeń po drodze lub urządzenia wysyłającego informacje o przepływach).
Domyślnie informacje o źródłowym i docelowym BGP ASN, wskazują na ASN do którego należy prefiks. Istnieje możliwość wymuszenia, by wskazywane były BGP ASN sąsiadów, od których otrzymaliśmy ruch i do których zostanie on przekazany. Niemniej, nie ma możliwości zapisywania obydwóch informacji jednocześnie.
W dużych sieciach z dużą ilością ruchu, ilość eksportowanych informacji może być na tyle spora, że zmuszeni będziemy do rozłożenia ich na większą ilość kolektorów. Jeśli jednak część z tych informacji nie jest nam potrzebna, to możemy spróbować zmniejszyć ilość ruchu w sieci oraz danych, jaka generowana jest przez NetFlow i obciążenie kolektorów, poprzez ich wcześniejszą agregację. Umożliwia to wersja 8 (NetFlow v8). Kolektor może również posiadać funkcję agregacji danych, ale dzięki wersji 8 dochodzi do tego jeszcze przed ich eksportem. Wykorzystywane są do tego celu wcześniej wspomniane "Aggregation Caches".
Do eksportu informacji NetFlow w wersji 9 (NetFlow v9) wykorzystywane są szablony. Dzięki ich zastosowaniu, możliwe jest przesyłanie dowolnej grupy informacji z danych, jakie wspierane są przez urządzenie wysyłające i kolektor. Stąd warto upewnić się czy kolektor nie tylko wspiera format eksportu danych w wersji 9, ale także czy obsługuje wymagane przez nas dodatkowe pola i rozszerzenia. O ile nie powinno być problemu z obsługą tradycyjnych pól, jakie były obsługiwane w wersji 5, to warto sprawdzić każde inne. Wraz z wersją 9 pojawiła się możliwość definiowana dodatkowych pól, specyficznych dla producenta danego rozwiązania, które wysyła informacje o przepływach. W wyniku tego możemy natrafić na sytuację, że pomimo wsparcia naszego kolektora dla wersji 9, niektóre informacje nie będą gromadzone i prezentowane.
Wersja 10 określana jest jako IPFIX (Internet Protocol Flow Information Export). Jest to opisany przez IETF standard eksportu danych NetFlow na bazie NetFlow v9 (ma względem niej kilka ograniczeń).
Informacja o przepływach zbierane są w pamięci "Main Cache". Dostęp do nich można uzyskać za pomocą polecenia trybu EXEC: "show ip cache flow". Przykład wydruku tego polecenia wraz z interpretacją widać na poniższym slajdzie.
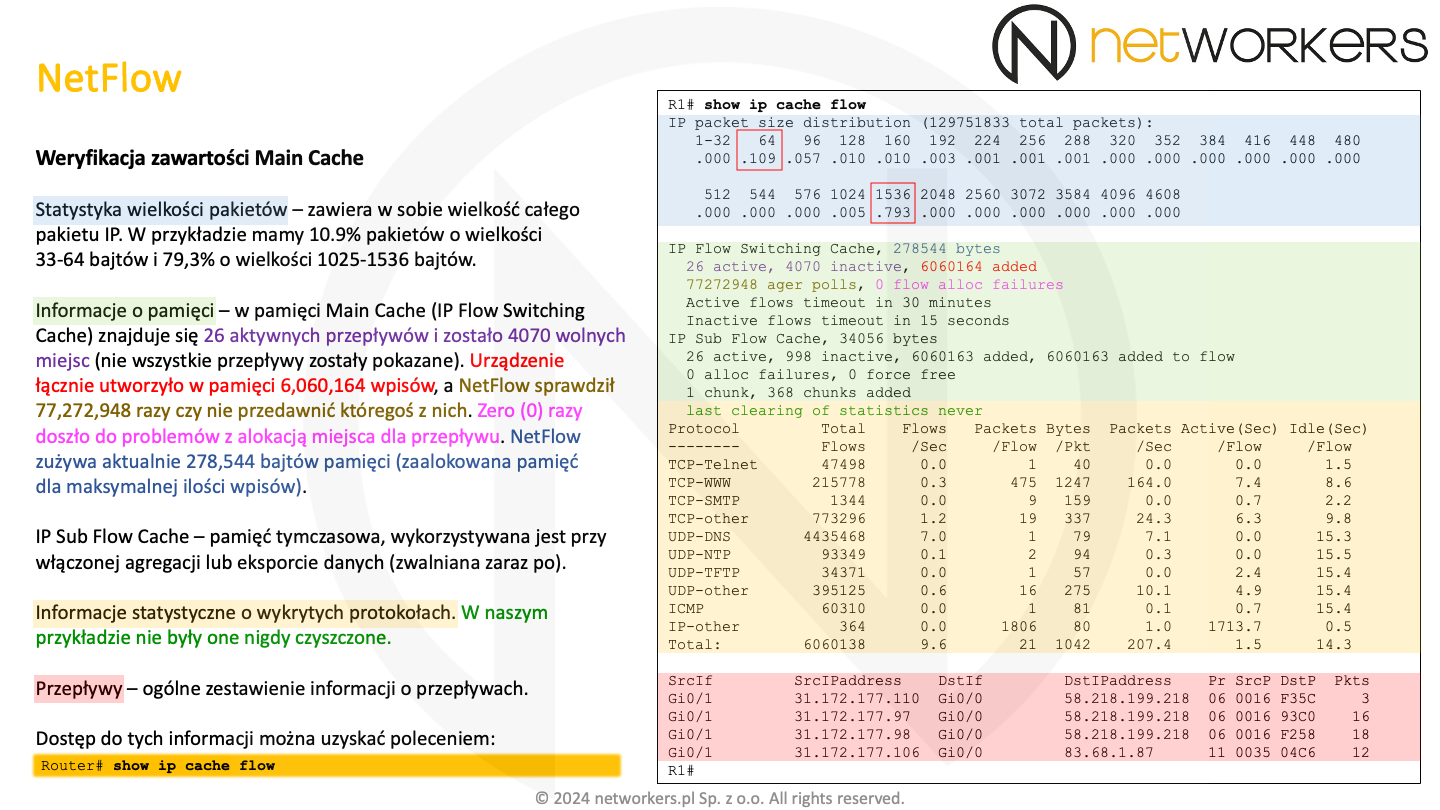
"IP Sub Flow Cache" wykorzystywane jest przy aktywnej agregacji lub eksporcie danych. Trafiają tam tymczasowo przepływy, które wygasły w "Main Cache". Ilość wpisów aktywnych rośnie, kiedy dane trafiają do eksportu/zagregowania, a spada kiedy zostanie to wykonane, np. zostanie wysłany pakiet do kolektora. Pamięć ta składa się z kawałków po 1024 bajty (chunk).
Na poprzednim slajdzie widać tylko podstawowe informacje o przepływach. Dostęp do ich rozszerzonej wersji uzyskuję się poprzez polecenie trybu EXEC: "show ip cache verbose flow". Przykładowy wynik tego polecenia można zobaczyć poniżej. Jego początkowa część jest taka sama, jak na slajdzie wyżej. Natomiast zestawienie informacji o przepływach zawiera o wiele większą ilość pól.
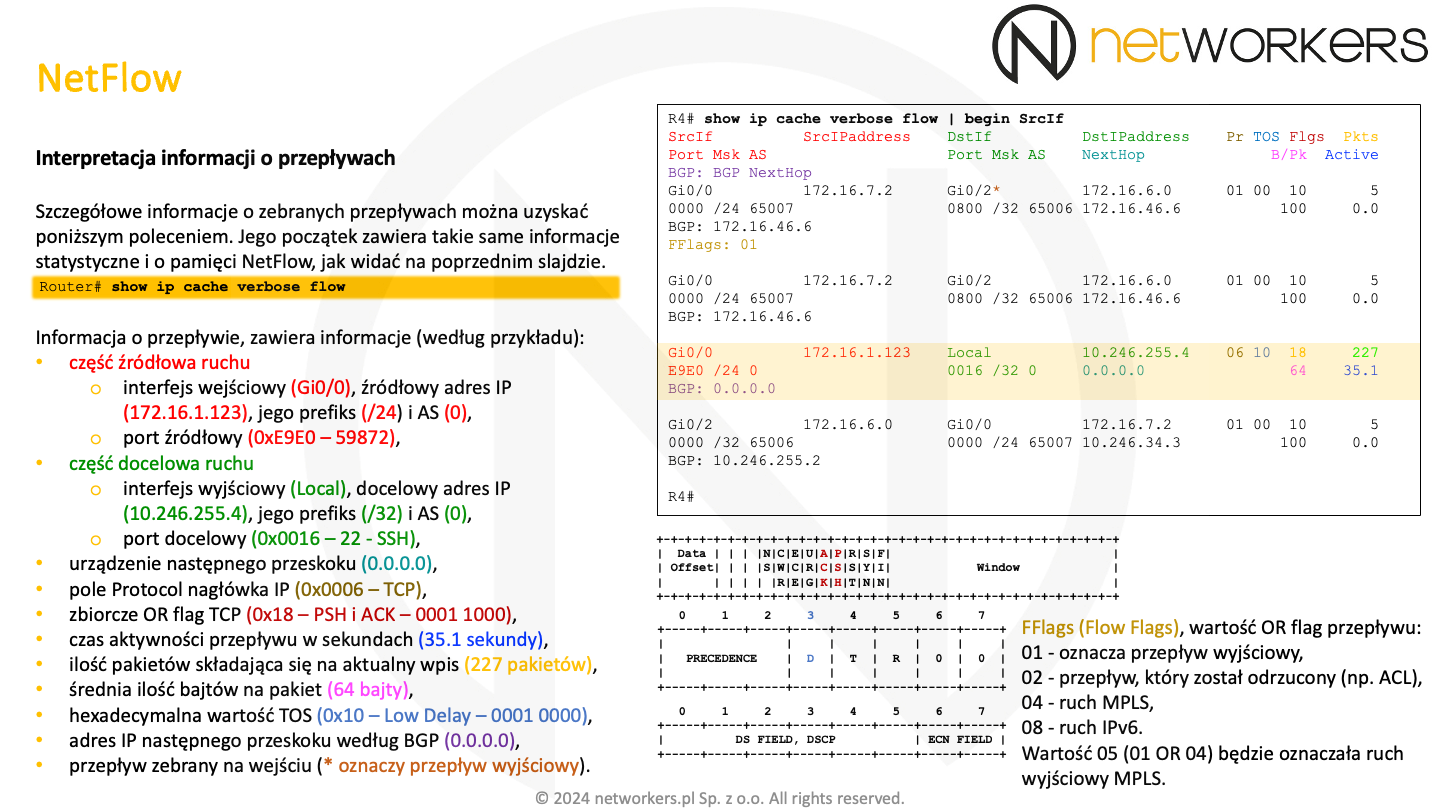
Zanim zaczniemy interpretować informacje o przepływie, warto zwrócić uwagę na "*", jaka pojawia się w pierwszym rekordzie w polu interfejsu docelowego ("DstIf"). Wskazuje ona, że informacje te zostały zebrane na wyjściu (ang. egress) oznaczonego gwiazdką interfejsu. Pomimo tego, że do wygenerowania danych dla tego przykładu uruchomiliśmy zbieranie informacji o przepływach na wejściu i wyjściu interfejsu "Gi0/0", to widać, że informacje zbierane są tylko na jego wejściu. Wynika to z tego, że na interfejsie tym został skonfigurowany MPLS. Zatem z punktu widzenia interfejsu, nie ma na nim wyjściowego ruchu IP. Aby ruch ten dało się zbierać, wymagana jest dodatkowa konfiguracja MPLS-aware NetFlow.
W tym samym, pierwszym rekordzie, widać też pole "FFlags (Flow Flags)", którego wartość tworzy sumę OR jednej lub większej ilości flag przepływu. "01" oznacza przepływ wyjściowy, "02" przepływ, który został odrzucony (na przykład, na skutek działania listy ACL), "04" ruch MPLS, a "08" ruch IPv6. Zatem, dla przykładu wartość "05" ("01" OR "04") będzie oznaczała ruch wyjściowy MPLS.
Do tej pory nie interpretowaliśmy wszystkich informacji, jakie można odczytać z rekordu. Są one zestawione w legendzie, która wyświetlana jest w pierwszych wierszach zestawienia przepływów. "SrcIf" i "DstIf", są skrótami od odpowiednio "Source Interface" i "Destination Interface". Poniżej nich są informacje, odnoszą się do odpowiednio części źródłowej i docelowej wartości pól:
- "Port" - zwykle numer portu TCP/UDP (wartość heksadecymalna),
- "Msk" - wielkość prefiksu/długość maski (wartość dziesiętna)
- "AS" - BGP ASN (wartość dziesiętna).
Kolumny "SrcIPaddress" i "DstIPaddress" oznaczają odpowiednio źródłowy i docelowy adres IP. Dalej znajduje się kolumna "Pr", która oznacza numer protokołu z nagłówka IP (wartość heksadecymalna). Dla przykładu, "Pr" równe 0x01 oznacza ICMP, 0x06 TCP, a 0x11 (dziesiętnie 17) oznacza UDP. Dalej, kolejno mamy wartość bajtu "TOS" (wartość heksadecymalna) i zbiorcze OR flag TCP w miejscu oznaczonym jako "Flgs" (wartość heksadecymalna). Poniżej flag znajduje się średnia ilość bajtów na pakiet - "B/Pk". Ostatnia kolumna zawiera informacje na temat ilości pakietów ("Pkts") składających się na aktualny wpis. Zaraz poniżej, w miejscu "Active" znajduje się czas aktywności przepływu w sekundach. Należy pamiętać, że kiedy informacja zostanie wyeksportowana, na skutek minięcia licznika "active" (więcej na kolejnym slajdzie), to czas dla nowych pakietów składających się na nowy rekord przepływu liczony jest od zera. Na końcu, u samego dołu znajduje się informacja na temat adresu IP następnego przeskoku według BGP ("BGP: BGP NextHop"). Ma wartość 0.0.0.0, jeśli w tablicy routingu nie ma wpisu BGP dla docelowego adresu IP. Została jeszcze wartość "NextHop", która wskazuje adres IP urządzenia następnego przeskoku, na drodze do docelowego adresu IP.
Interfejsem wejściowym jest "Gi0/0", a wyjściowym interfejs Local. Oznacza to, że ruch kierowany jest do urządzenia, które zbiera informacje o przepływach (stąd też pola "NextHop" i "BGP NextHop" mają wartość 0.0.0.0). Adres 10.246.255.4, jest adresem Loopback interfejsu routera R4, z którego pochodzi informacja o tym przepływie. Po wartości 0x06 w miejscu "Pr" (TCP) i 0x0016 w miejscu "Dst Port", możemy zorientować się, że jest to sesja SSH (0x16 to 22 dziesiętnie), nawiązana z portu źródłowego 59872 (0xE9E0). W tablicy routing R4, dla adresów IP 172.16.1.123 i 10.246.255.4 znajduje się długość prefiksu odpowiednio /24 i /32.
Wartość "TOS" wynosi 0x10, co bitowo daje wartość "0001 0000". Wartość ta, nie pasuje do żadnej z klas DSCP (CS, AF, EF), ale oznacza Low Delay w przypadku interpretacji TOS (D = 1). Powyżej na slajdzie widoczna jest budowa tego pola w interpretacji TOS.
Zbiorcze flagi TCP (OR), czyli wszystkie widziane w tym przepływie, mają wartość 0x18 (0001 1000), co wskazuje na obecność flag PSH i ACK. Zapewne flaga SYN też pojawiła się w tym połączeniu jeszcze przed skonfigurowaniem usługi NetFlow (w trakcie nawiązywania połączenia SSH). Poniżej widać fragment nagłówka TCP z flagami.
Na przepływ ten składa się 227 pakietów, gdzie średnia ilość bajtów na pakiet to 64. Jest on aktywny od 35.1 sekundy.
"Main Cache" przetrzymuje tylko informacje o aktywnych przepływach. Urządzenie zakłada, że przepływ wygasł, jeśli:
- połączenie TCP zostało zamknięte (FIN) lub zresetowane (RST),
- brak jest ruchu związanego z danym przepływem ("inactive time", domyślnie 15 sekund),
- żyje zbyt długo ("active time", domyślnie 30 minut).
Zmianę domyślnych wartości dla przetrzymywania przepływów w "Main Cache" można dokonać poleceniami trybu konfiguracji globalnej: "ip flow-cache timeout inactive" i "ip flow-cache timeout active", odpowiednio dla wpisów nieaktywnych i aktywnych.

Z każdym pakietem aktywnego przepływu aktualizowane są dane na jego temat i resetowana jest wartość czasu "inactive". Licznik czasu "active" rozpoczyna swoje działanie z pierwszym pakietem dla danego przepływu. Po jego wygaśnięciu, przepływ może zostać wysłany do kolektora i jeśli tylko ruch związany z tym przepływem nadal istnieje, to na jego miejscu pojawia się identyczny wpis, dla którego zbierane są nowe dane statystyczne. Z każdym wyeksportowanym przepływem powiązane są informacje czasowe ("Start Time" i "End Time"), dzięki którym kolektor jest w stanie scalić je w jeden przepływ. Przepływy usuwane są z "Main Cache" również w przypadku braku miejsca (zapełnienia). Gdy zacznie brakować miejsca przyjmuje się, że w pierwszej kolejności wygaśnięciu podlegają przepływy, które są najstarsze. Ale tak naprawdę, już kiedy zaczyna go brakować, załączana jest specjalna funkcja heurystyczna, której zadaniem jest szybsze wygasanie przepływów (szybsze, niż wartość licznika "inactive"). Domyślnie "Main Cache" obsługuje 4096 przepływów, co można zmienić poleceniem trybu konfiguracji globalnej "ip flow-cache entries".
Zwiększając ilość obsługiwanych przepływów, należy pamiętać o tym, że jeden wpis potrzebuje minimum 64 bajtów pamięci. Zatem dla 65536 wpisów będziemy potrzebować minimum 4MB pamięci. Minimum, gdyż ilości informacji przetrzymywanych o każdym przepływie można rozszerzyć. Poniżej można zobaczyć pełną zawartość "Main Cache". Oprócz samych przepływów, znajdują się tam informacje statystyczne oraz informacje o wykorzystaniu i konfiguracji "Main Cache". Wdać, że aktualnie w pamięci ("IP Flow Swiching Cache") jest 37 aktywnych wpisów i zostało 4059 wolnych miejsc na przepływy (przepływy nie zostały pokazane).
Informacje statystyczne NetFlow można wyczyścić z użciem polecenia trybu EXEC: "clear ip flow stats". Zeruje i usuwa ono fragmenty oznaczone fioletowym kolorem na zrzucie poleceń powyższego slajdu (wyjątkiem są informacje nagłówkowe i legendy).
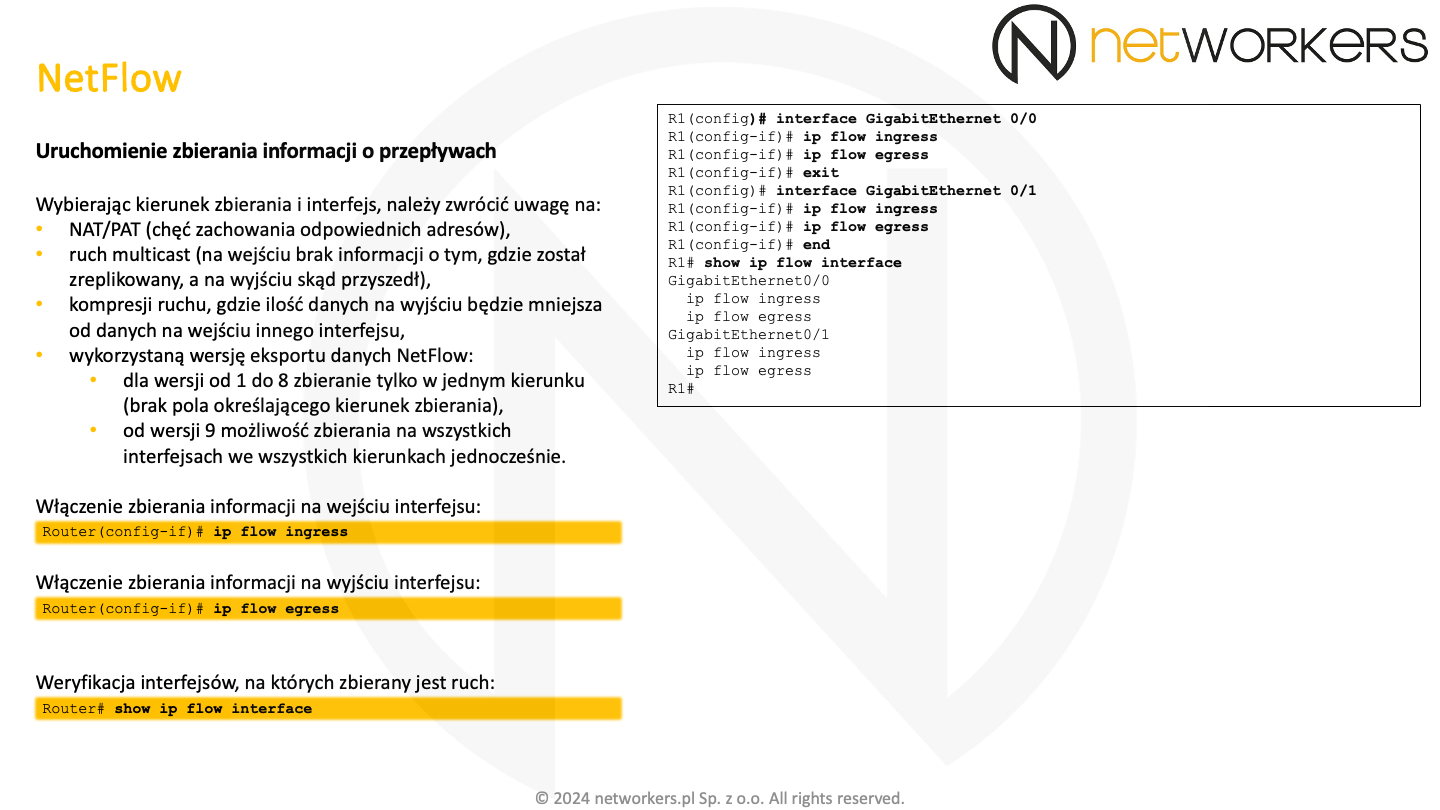
Aby uruchomić zbieranie danych z NetFlow, należy wejść do konfiguracji wybranego interfejsu i użyć polecenia "ip flow ingress" (zbieranie danych na wejściu) i/lub "ip flow egress" (zbieranie danych na wyjściu), w zależności od tego czy chcemy uruchomić zbieranie danych o ruchu na wejściu interfejsu, wyjściu interfejsu czy może w obu kierunkach. Po wydaniu powyższych poleceń, urządzenie zacznie zapełniać "Main Cache" informacjami o przepływach.
Wybierając kierunek zbierania danych o ruchu oraz interfejs, należy zwrócić uwagę na:
- NAT/PAT (chęć zachowania odpowiednich adresów),
- ruch multicast (na wejściu brak informacji o tym, gdzie został zreplikowany, a na wyjściu skąd przyszedł),
- kompresji ruchu, gdzie ilość danych na wyjściu będzie mniejsza od danych na wejściu innego interfejsu,
- wykorzystaną wersję eksportu danych NetFlow:
- dla wersji od 1 do 8 zbieranie tylko w jednym kierunku (brak pola określającego kierunek zbierania),
- od wersji 9 możliwość zbierania na wszystkich interfejsach we wszystkich kierunkach jednocześnie.
Do weryfikacji interfejsów, na których zbierane są dane o przepływach służy polecenie trybu EXEC: "show ip flow interface".
Wraz z wersją 9 zostało wprowadzone wsparcie dla zbierania informacji na wyjściu interfejsu. Da się tak zebrane informacje eksportować z użyciem niższych wersji formatu eksportu danych NetFlow. Niemniej, należy być wtedy szczególnie ostrożnym, gdyż eksportowane dane nie zawierają informacji na temat kierunku w jakim zostały zebrane. Zatem, lepiej tego nie robić.
Jeśli na niektórych interfejsach będziemy zbierać dane na wejściu, a na niektórych na wyjściu, to może poskutkować to duplikacją danych i niestety kolektor NetFlow nie będzie w stanie tego wykryć. Stąd przyjmuje się, że zbieranie informacji na wyjściu interfejsu obsługiwane jest od wersji 9, a dla niższych wersjach konfiguruje się zbieranie informacji na wejściu.
W przypadku wersji 9 nie ma z tym problemu, gdyż eksportuje on informację na temat kierunku w jakim zostały zebrane dane (domyślnie Traditional NetFlow eksportuje taką informację). Oznacza to, że wraz z wersją 9, możemy zbierać dane na wejściu i wyjściu każdego z interfejsów jednocześnie, a nawet to dowolnie mieszać i kolektor będzie mógł sobie z tym poradzić.
Zbieranie informacji na wyjściu interfejsu najczęściej wykorzystywane jest przy:
- kompresji ruchu, gdzie ilość danych na wyjściu interfejsu będzie mniejsza niż na interfejsie wejściowym,
- ruchu multicast, gdyż zbierając dane na wejściu, nie ma informacji gdzie zostanie on zreplikowany,
- chęci zachowania w rekordach odpowiednich adresów na urządzeniu realizującym NAT.
W rekordzie przepływu, który został zebrany na wyjściu interfejsu, polem kluczowym jest domyślnie interfejs wyjściowy. Jeśli chcemy to zmienić, należy posłużyć się poleceniem trybu konfiguracji globalnej: "ip flow-egress input-interface".
Obsługa przepływów w lokalnej pamięci urządzenia i eksport danych do kolektora to dwie różne rzeczy. To, co z lokalnej pamięci trafi do kolektora NetFlow, będzie zależne od wybranej wersji formatu eksportu danych NetFlow. Mamy możliwość eksportu informacji do maksymalnie dwóch kolektorów per cache. Na slajdzie poniżej znajdują się przykładowe polecenia umożliwiające skonfigurowanie wersji eksportu danych oraz zewnętrznych kolektorów NetFlow (adres IP i numer portu UDP).

Domyślną wersją eksportu danych jest wersja 1. Zatem jedyne co musimy zrobić, by z niej korzystać, to zdefiniowanie kolektora z użyciem polecenia trybu konfiguracji: "ip flow-export destination" i opcjonalnie wskaznie interfejsu źródłowego (warto użyć do tego celu interfejs Loopback, co zagwarantuje nam niezmienność adresu IP, który to powinien być taki sam dla wszystkich danych wysyłanych z jednego urządzenia). Służy do tego polecenie trybu konfiguracji globalnej: "ip flow-export source".
Jeżeli chcemy eksportować dane z wersją inną niż domyślna (wersja 1), należy ją wskazać z użyciem polecenia trybu konfiguracji globalnej: "ip flow-export version". W przypadku wersji 5 i 9 będziemy mogli też podać w nim dodatkowe parametry, związane z obsługą danych protokołu BGP. Domyślnie, informacje o źródłowym i docelowym BGP ASN, wskazują ASN do którego należy prefiks (parametr "origin-as"). Istnieje możliwość wymuszenia, by wskazywane były BGP ASN sąsiadów, od których ruch otrzymaliśmy i do których jest on wysłany (parametr "peer-as"). Niemniej, nie ma możliwości zapisywania obydwóch informacji. Istnieje również możliwość dodania do "Main Cache" informacji na temat BGP Nexthop. Przy czym należy pamiętać, iż pole to nie jest obsługiwane przez NetFlow v5. Służy do tego celu parametr "bgp-nexthop".
Informacje o ustawionych kolektorach NetFlow, wybranej wersji eksportu formatu danych NetFlow, dodatkowych opcjach eksportu oraz danych statystycznych o wysłanych pakietach można zweryfikować z użyciem polecenie trybu EXEC: "show ip flow export".
Poniżej zostały pokazane zrzuty zawartości pakietów z danymi NetFlow w wersji 1 (po lewej) i wersji 5 (po prawej). Tak wyglądają dane eksportowane z urządzenia do zewnętrznego kolektora NetFlow.
Standardowy nagłówek w wersji 1 zawiera informacje na temat wersji (1), ilości przenoszonych przepływów i informacje czasowe. Dalej znajdują się już informacje o poszczególnych przepływach (każdy w oddzielnym "pdu").

Warto zwrócić w nich uwagę na wszystkie pola. Te dodatkowo obsługiwane przez wersję 5 zostały oznaczone kolorem.
Standardowy nagłówek dla wersji 5 zawiera informacje na temat wersji (5), ilości przenoszonych przepływów, informacje czasowe i numer sekwencyjny przepływów. Jest to numer początkowy, co oznacza że w kolejnym pakiecie powinien on urosnąć o ilość wysłanych przepływów w bieżącym pakiecie, która wynosi 18 (Count). Zatem kolejny pakiet powinien posiadać FlowSequence równe 150. Dalej widać poszczególne przepływy (każdy w oddzielnym "pdu").
W NetFlow v9 mamy szablony opisujące opcje i szablony opisujące dane. W związku z możliwością zagubienia datagramu UDP, są one domyślnie wysyłane co 20 pakietów lub co 30 minut.

Wartości te można modyfikować dla każdego z rodzaju szablonów niezależnie. Służą do tego odpowiednio polecenia trybu konfiguracji globalnej: "ip flow-export template timeout-rate" i "ip flow-export template refresh-rate" dla szablonów danych oraz "ip flow-export template options timeout-rate" i "ip flow-export template options refresh-rate" dla szablonów opcji.
Dodatkowo można włączyć eksport informacji o wysłanej do kolektora ilości pakietów oraz przepływów. Służy do tego polecenie trybu konfiguracji globalnej: "ip flow-export template options export-stats".
Z każdą zmianą parametrów i co za tym idzie informacji, które mają być eksportowane, ulegają zmianie informacje na temat eksportowanych szablonów. Widoczne są one z użyciem polecenia trybu EXEC: "show ip flow export template".
Do 9 wersji eksportu danych NetFlow rekordy miały stałą budowę, stąd kolektor zawsze wiedział jak interpretować otrzymane informacje. Elastyczność w wyborze eksportowanych danych i budowie rekordów NetFlow v9 skomplikowała nieco sytuację. Rekordy mogą składać się nie tylko z wybranej części dobrze znany pól, ale też istnieje możliwość definiowania nowych.
Aby kolektor radził sobie z przesyłanymi do niego rekordami, musi wcześniej otrzymać instrukcję ich czytania. Są nią szablony rekordów, które zawierają listę pól składających się na rekord oraz ich typ i wielkość. Jako, że do kolektora możemy wysyłać różne rekordy, z różnymi polami, to każdy z takich szablonów identyfikowany jest numerem ID. Numer ten zawiera też każdy zbiór rekordów danych ("FlowSet"). Dzięki temu istnieje możliwość powiązania tych informacji ze sobą. Podobna sytuacja ma miejsce podczas eksportu opcji. Tak więc w NetFlow v9 mamy szablony rekordów i rekordy oraz szablony opcji i opcje. Szablony są niczym innym, jak instrukcjami, mówiącymi kolektorowi, jak czytać otrzymane informacje.
Na widoczny z lewej strony poniższego slajdu problem można natrafić podczas korzystania z analizatora pakietów. Dopóki nie otrzyma on szablonu dla danych NetFlow v9 nie wie, jak powinny być one interpretowowane.

Rekordy, opcje, szablony rekordów i szablony opcji mogą być przesyłane w tym samym pakiecie. Jako, że możemy eksportować wiele różnych rekordów i opcji, to szablonów tych także może być wiele. Są one identyfikowane przez ID, które określa wysyłający.
Powyżej możemy zobaczyć zrzut pakietu z danymi NetFlow, który zawieraja jeden szablon opcji i dwa szablony rekordów. Dodatkowo, w pakiecie tym znajdują się zbiory rekordów ("FlowSet") z przepływami/rekordami ("flows"), które identyfikowane są tym samym numerem ID, co odpowiadający im szablon. W każdym zbiorze rekordów zawarta jest informacja na temat ich ilości.
Szablon zawiera informacje na temat ilości pól oraz ich typu i wielkości. Poniżej widać szablon opcji, który zawiera informacje o wysłanej do kolektora ilości pakietów i przepływów. Na slajdzie poniżej, z prawej strony znajdują się dane odpowiadające szablonowi z lewej. Warto zwrócić uwagę na ten sam ID ("Template ID" i "FlowSet ID").

Szablon ten aktywowany jest poleceniem trybu konfiguracji globalnej: "ip flow-export template options export-stats".
Poniżej zostały pokazane dwa zrzuty pakietów dla NetFlow w wersji 9. Zawartość pierwszego pokazuje zawartość szablonu rekordu danych. Widać ją po stronie lewej. Po stronie prawej został pokazany odpowiadający temu szablonowi pakiet z danymi rekordu.

Na tym etapie warto dokładnie przeanalizować budowę obydwu pakietów.
Pojawienie się szablonów ułatwiło definiowanie nowych pól rekordów. Nie są do tego celu już wymagane nowe wersje eksportu danych NetFlow, jak to było wcześniej, ze względu na ich stały oraz sztywny format.
Traditional NetFlow umożliwia dołożenie dodatkowych pól opisujących nagłówek protokołu IPv4, pole "Type" i "Code" nagłówka protokołu ICMP oraz takie informacje warstwy drugiej, jak źródłowy i docelowy adres MAC oraz numer VLAN (źródłowy i docelowy). Dla przypomnienia, na poniższym slajdzie został pokazany nagłówek IPv4, gdzie widać oznaczone zarówno zbierane wcześniej pola (ciemnoczerwona czcionka), jak i nowe pola (pomarańczowa czcionka).

Zbieranie wyżej wspomnianych informacji, uruchamia się poleceniem trybu konfiguracji globalnej: "ip flow-capture".
Użycie szablonów przyczyniło się do łatwego rozszerzenia zbieranych informacji o dane IPv6 i MPLS (Multiprotocol Laber Switching) oraz informacje z L2, jak numer VLAN i adres MAC. Stała się również możliwa analiza ruchu multicast względem jego replikacji oraz możliwość zbierania takich danych, jak różnica w opóźnieniu pomiędzy pakietami (ang. jitter), ilość zgubionych pakietów (ang. packet loss) czy czas podróży pakietu (ang. round trip time). Dane te mogą być kluczowe dla ruchu VoIP i wideo. W przypadku, kiedy urządzenie zbierające dane obsługuje DPI (Deep Packet Inspection), możliwe jest nawet zbieranie informacji na temat wykorzystywanych w sieci aplikacji/protokołów (np. NBAR firmy Cisco Systems).
NetFlow Dynamic Top Talkers jest podobnym w działaniu narzędziem do NetFlow IP Top Talkers. Niemniej, nie wymaga ona żadnej wcześniejszej aktywacji. Wystarczy, że na urządzeniu uruchomione jest zbieranie informacji o przepływach. Wszystkie potrzebne nam raporty są dynamicznie generowane na podstawie znajdujących się w "Main Cache" informacji. W związku z tym, że wszystkie dane są generowane dynamicznie, nie ma do nich dostępu SNMP poprzez odpowiednie wartości MIB. Usługa ta, tak samo jak Tradictional NetFlow (TNF) ograniczona jest do przepływów IPv4.

NetFlow Dynamic Top Talkers wykorzystuje polecenie trybu EXEC: "show ip flow", gdzie po parametrze "top" należy wskazać jaka ilość najbardziej aktywnych przepływów nas interesuje. Dalej, z użyciem odpowiednich parametrów tego polecenia można dokonać także agregacji (parametr "aggregate"), zawężania (parametr "match") i sortowania (parametr "sorted-by").
Powyżej znajduje się kilka przykładów użycia NetFlow Dynamic Top Talkers. W pierwszym widać dwa porty docelowe, do których nawiązane jest najwięcej połączeń (22 - SSH, 646 - LDP). W drugim dwa docelowe adresy IP, do których generowane jest najwięcej pakietów. A w trzecim trzy porty źródłowe z przedziału od 0 do 1024 z największą ilością bajtów (22 - SSH, 646 - LDP, 123 - NTP).
Jak widać, narzędzie to nadaje się świetnie do szybkiej analizy, diagnozy i rozwiązywania problemów w sieci.
NetFlow Dynamic IP Top Talkers jest naprawdę przydatną funkcjonalnością, szczególnie, kiedy potrzebna nam szybka weryfikacja przechodzącego przez urządzenie ruchu. Ręczne analizowanie całej zawartości "Main Cache" w środowisku produkcyjnym jest za bardzo czasochłonne, a wręcz i niemożliwe. Dzięki tej funkcjonalności szybko można uzyskać informację na temat adresów IP, które pobierają najwięcej danych czy usług, które generują najwięcej ruchu w danej chwili.
Na końcu warto dodać, że TNF (Tradictional NetFlow) stosuje predefiniowane przez producenta szablony, do których możemy dodać zaledwie kilka pól. FNF (Flexible NetFlow) umożliwia samodzielne budowanie szablonów od podstaw. My zaczęliśmy od TNF jako, że jest o wiele prostszy w konfiguracji i łatwiej skupić się na tym, co na ten moment istotne, czyli sposobie działania i idei NetFlow. Dodatkowo TNF da się uruchomić nawet na dość starych platformach, co dla niektórych może być kluczowe.
Przed kolejną porcją wiedzy zachęcamy do przećwiczenia i utrwalenia tej poznanej tutaj. Skorzystaj z naszych ćwiczeń!