")
")
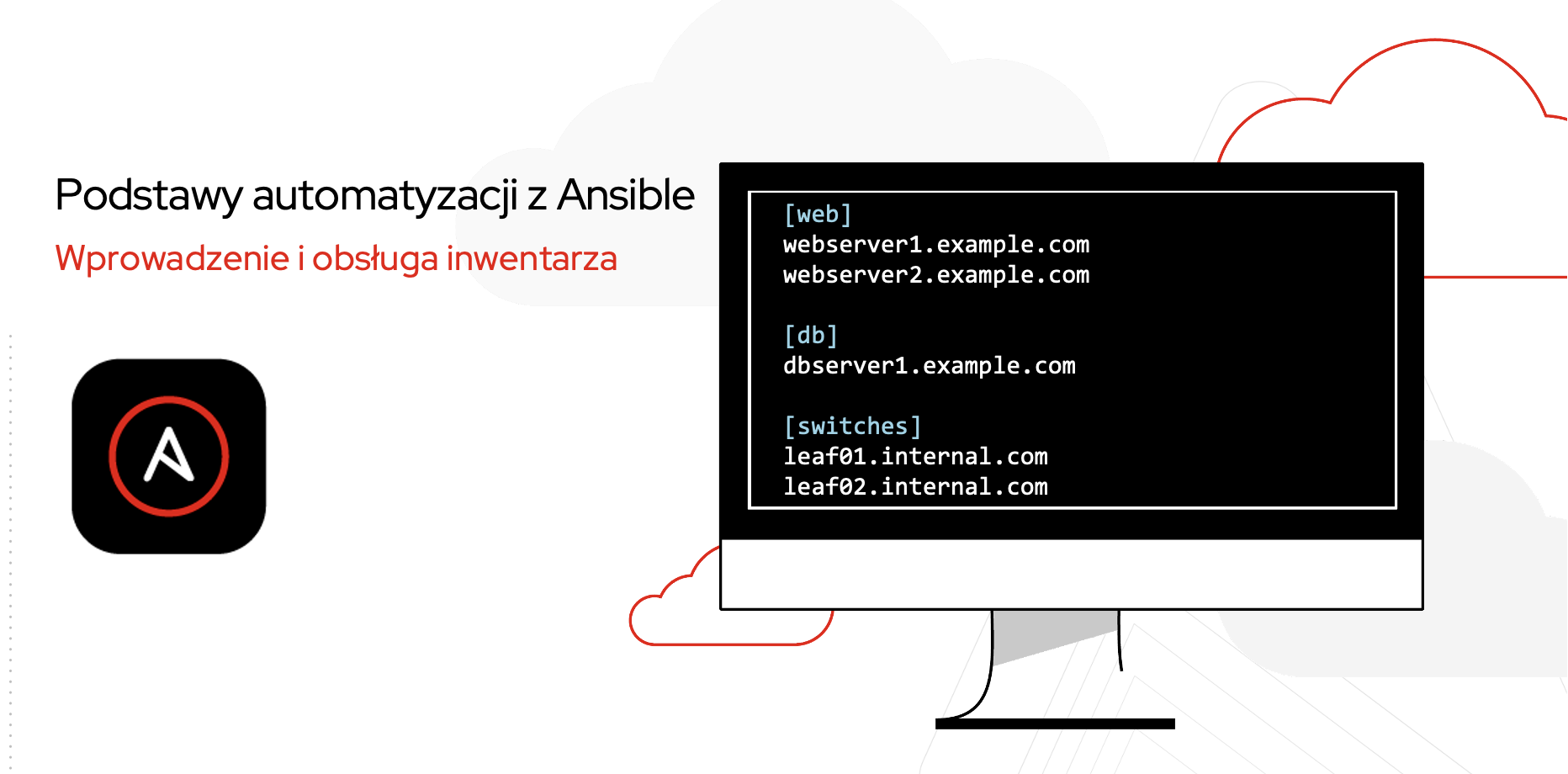
Podstawy automatyzacji z Ansible: Wprowadzenie i obsługa inwentarza
Ręczne wprowadzanie zmian jest żmudne, podatne na błędy i problematyczne pod względem dokumentowania. Ansible rozwiązuje wszystkie te problemy. Świetnie nadając się do tego, czego my nie lubimy. Jest tym wykonywanie tej samej czynności na wielu elementach. Dodatkowo, powstały do tego celu plik YAML, z którego korzysta Ansible, staje się pewną formą dokumentacji. Na pewno nie zastąpi on typowej dokumentacji ze schematami, tabelami oraz dodatkowymi uwagami. Natomiast jest to dobry punkt odniesienia, kiedy chcemy sprawdzić co jak zostało czy powinno być skonfigurowane.
Ansible umożliwia opisanie infrastruktury oraz jej usług za pomocą kodu (ang. IoC - Infrastructure as Code). Jeżeli dodatkowo zadbamy o odpowiednie komentarze oraz porządek w strukturze plików, to Ansible może zastąpić całkiem pewne elementy typowej dokumentacji, szczególnie te dynamiczne, które wymagają częstej aktualizacji.
Stworzenie takiego kodu może wydawać się sporą inwestycją czasu, niemniej wcale tak nie jest, a długofalowo się to opłaci. Kiedy będziemy potrzebowali skonfigurować kolejne elementy infrastruktury w podobny sposób, to łatwo będzie można to zrobić. Bez dokładnej analizy konfiguracji tego co już jest oraz bez obawy o to, że coś przeoczymy czy zrobimy inaczej.
Niemniej, w tym wszystkim bardzo istotna jest dobra znajomość tego co będziemy automatyzować. Tego nie zastąpi nam żadne narzędzie. Tak samo szybko możemy wdrożyć zarówno "złą", jak i "dobrą" konfigurację. Dlatego najlepiej, kiedy tym zajmują się doświadczeni eksperci w danej dziedzinie. Cała reszta, związana z wykorzystaniem do tego celu Ansible jest już bardzo prosta.
Ansible jest narzędziem do automatyzacji o otwartym kodzie (ang. Open Source). Powstało w 2012 roku, a od 2015 roku stało się własnością firmy Red Hat. Cechuje go bezagentowość, prostota i bardzo duże możliwości.
Nadaje się do automatyzacji nie tylko rozwiązań Red Hat, czy systemów z rodziny GNU/Linux. Z powodzeniem jest stosowany w automatyce rozwiązań Microsoft, środowisk DevOps, usług chmurowych, platform do kontenerów i wirtualizacji, a nawet całych centrów danych czy sieci. Ilość zastosowań i obsługiwanych produktów przez Ansible ciągle rośnie.
O ile Ansible może być wykorzystywane do automatyzacji różnych elementów infrastruktury IT, to musi się to odbywać z systemu GNU/Linux lub Unix. W naszym przykładzie będzie to dokładnie system RHEL10 (Red Hat Enterprise Linux w wersji 10).
Starsze wersje Ansible zawierały w sobie bardzo dużą ilość różnych modułów. Niestety, przestało się to skalować wraz ze wzrostem popularności tego narzędzia. Abyśmy szybciej mogli korzystać z nowego modułu czy też nowej wersji danego modułu, a też nie musieli zawsze pobierać modułów, które nie są nam potrzebne, zostały one wydzielone do Ansible Content Collections.
Pozostała część, tworząca Ansible Core, zawiera w sobie tylko bazowe elementy Ansible. Umożliwia uruchamianie playbooków oraz zapewnia kluczowe funkcje, jak pętle, warunki i inne imperatywy dla kodu automatyzującego. Dodatkowo, aby pozbyć się konfliktów nazewniczych, zostały wprowadzone przestrzenie nazw (ang. namespace). Dla przykładu, w ramach Ansible Core dostajemy dostep do modułów znajdujących się w przestrzeni nazw "ansible.builtin". Skutkiem tych zmian, należy poprzedzać nazwę każdego modułu, nazwą przestrzeni nazw, w której się on znajduje (np. moduł "dnf" to teraz "ansible.builtin.dnf").
Red Hat dostarcza Ansible Core w formie pakietu RPM o nazwie "ansible-core". Jest on dostępny w ramach systemów RHEL9 i RHEL10 w repozytorium AppStream. Sposób instalacji Ansible Core w systemach RHEL9 i RHEL10 został przedstawiony poniżej:
[root@vm0-net ~]# dnf install ansible-core
Należy jednak pamiętać, że w ramach subskrypcji dla systemu Red Hat Enterprise Linux istnieje jedynie limitowane wsparcie dla Ansible. Zamyka się ono w obszarze dostarczanych przez Red Hat roli do automatyzacji konfiguracji systemów RHEL (pakiet o nazwie "rhel-system-roles"), generowanych przez Red Hat Insights playbooków wdrażających zalecenia usprawniające działanie tych systemów, w tym poprawę ich wydajności i bezpieczeństwa oraz playbooki powiązane z dostosowaniem systemów RHEL do odpowiednich norm, które potrafi generować z użyciem OpenSCAP m.in. Red Hat Satellite i Red Hat Insights.
Narzędzie Ansible dostępne jest w systemie RHEL bez żadnych dodatkowych opłat, zgodnie ze wskazanymi wyżej ograniczeniami.
Dodatkowo, firma Red Hat udostępnia certyfikowane moduły, wtyczki, role i całe kolekcje w ramach swojego Automation Hub. Można uzyskać do nich dostęp po wykupieniu subskrypcji dla Red Hat Ansible Automation Platform.
Zainteresowanych ich zakupem zapraszamy do
Stosowanie inwentarza w Ansible
Zanim zaczniemy automatyzować, musimy zdefiniować inwentarz (ang. inventory) na którym będziemy działać. W najprostszej postaci może być on statycznym plikiem tekstowym w formacie INI lub YAML (ang. static inventory). Istnieje także możliwość korzystania z dynamicznego inwentarza (ang. dynamic inventory). Zaciągamy wtedy dane z innych rozwiązań, jak Red Hat Satellite, Red Hat Insights, Amazon EC2, Google Compute Engine, Microsoft Azure Resource Manager, VMware vCenter, VMware ESXi, OpenStack, Red Hat OpenShift Virtualization czy Terraform State lub poprzez dynamiczne skrypty z różnych baz danych.
Inwentarz składa się ze zbioru węzłów nazywanych hostami, jak urządzenia czy serwery, które mogą być w dowolny sposób pogrupowane. Mogą one przynależeć do wielu grup jednocześnie jak i nie przynależeć do żadnej. Członkami jednej grupy mogą być także inne grupy podrzędne. Istnieją dwie grupy wbudowane "all" i "ungrouped". Do grupy "all" niejawnie przynależą wszystkie węzły z inwentarza, a do grupy "ungrouped" niejawnie przynależą wszystkie węzły z inwentarza, które nie są członkiem żadnej innej grupy. Wewnątrz inwentarza da się definiować zmienne powiązane ze znajdującymi się w nim obiektami grup i pojedynczych węzłów. O ile posłużyliśmy się tutaj terminem węzłów, to Ansbile w jego miejscu wykorzystuje termin hostów, bez względu na to, czy tymi węzłami są serwery fizyczne, instancje wirtualne, urządzenia sieciowe czy jeszcze coś innego.
Nie powinno się używać w nazwach grup pauzy ("-") oraz tej samej nazwy dla hosta i grupy w pliku inwentarza. W tym drugim przypadku, nazwa grupy zostanie pominięta i uwzględniony zostanie tylko host. W nazwach grup powinno się stosować tylko litery, cyfry oraz znak podkreślenia ("_"), przy czym cyfra nie może być pierwszym znakiem nazwy.
Najczęściej do budowy inwentarza stosuje się plik w formacie INI. Nim też będziemy się posługiwać w większości przykładów. Jego najprostszą postacią jest lista adresów IP oraz nazw domenowych (jeden/jedna per wiersz). Przykładowy plik inwentarza:
vm1-net.int.networkers.pl
vm2-net.int.networkers.pl
vm3-net.int.networkers.pl
vm4-net.int.networkers.pl
10.8.232.61
10.8.232.62
Format INI umożliwia tworzenie sekcji. Stosuje się do tego celu nawiasy kwadratowe ("[]"). W ten sposób definiuje się grupy w ramach inwentarza. Każda sekcja jest oddzielną grupą. Nazwa sekcji odpowiada nawie grupy. Z grup korzysta się bardzo często, gdyż najczęściej chcemy wykonać konkretne zadania na konkretnej grupie hostów.
Poniżej został pokazany przykładowy plik inwentarza, który dzięki grupom umożliwia wygodne wykonywanie operacji na wszystkich hostach o określonej funkcji lub ulokowanych w konkretnym centrum danych lub pracujących w danym środowisku.
[web_servers]
web1-net.int.networkers.pl
web2-net.int.networkers.pl
[db_servers]
db1-net.int.networkers.pl
db2-net.int.networkers.pl
[dns_servers]
10.8.232.61
10.8.232.62
[east_datacenter]
web1-net.int.networkers.pl
db1-net.int.networkers.pl
10.8.232.61
[west_datacenter]
web2-net.int.networkers.pl
db2-net.int.networkers.pl
10.8.232.62
[production]
web1-net.int.networkers.pl
web2-net.int.networkers.pl
db1-net.int.networkers.pl
db2-net.int.networkers.pl
10.8.232.61
10.8.232.62
[development]
vm1-net.int.networkers.pl
vm2-net.int.networkers.pl
10.8.232.123
10.8.232.124
Jak widać powyżej, sposób grupowania jest praktycznie dowolny.
Wspomnieliśmy też o możliwości tworzenia grup zagnieżdżonych, to znaczy grup składających się nie tylko z hostów, ale i z innych grup. Do tego celu wykorzystywany jest sufiks ":children", który dodaje się do nazwy grupy. Przykład wykorzystania grup zagnieżdżonych można zobaczyć poniżej, gdzie do grupy "db_and_web" przynależy grupa "web_servers" i "db_servers", a do grupy "production" zarówno grupy "web_servers" i "db_server", jak i dwa hosty "10.8.232.61" i "10.8.232.62".
[root@vm0-net ~]# cat inventoryvm1-net.int.networkers.pl
vm2-net.int.networkers.pl
10.8.232.123
10.8.232.124
[web_servers]
web1-net.int.networkers.pl
web2-net.int.networkers.pl
[db_servers]
db1-net.int.networkers.pl
db2-net.int.networkers.pl
[db_and_web:children]
web_servers
db_servers
[production]
10.8.232.61
10.8.232.62
[production:children]
web_servers
db_servers
[root@vm0-net ~]#
Warto zwrócić uwagę na to, że o ile grupa może zawierać hosty, jak i inne grupy, to dodaje się je w różnych sekcjach.
Użyjemy teraz polecenia do weryfikacji hostów przynależących do poszczególnych grup.
$ ansible -i <inventory_file> --list-hosts <group_name>
Za pomocą opcji "-i" wskazujemy plik inwentarza o nazwie "inventory", a opcja "--list-hosts" wyświetla hosty należące do zadanej grupy. Widać poniżej, że do grupy "web_servers" i "db_servers" przynależą po 2 hosty:
[root@vm0-net ~]# ansible -i inventory --list-hosts web_servers
hosts (2):
web1-net.int.networkers.pl
web2-net.int.networkers.pl
[root@vm0-net ~]# ansible -i inventory --list-hosts db_servers
hosts (2):
db1-net.int.networkers.pl
db2-net.int.networkers.pl
[root@vm0-net ~]#
Zatem do grupy "db_and_web" przynależą 4 hosty jako, że jej członkami są grupy "db_servers" i "web_servers":
[root@vm0-net ~]# ansible -i inventory --list-hosts db_and_web
hosts (4):
web1-net.int.networkers.pl
web2-net.int.networkers.pl
db1-net.int.networkers.pl
db2-net.int.networkers.pl
[root@vm0-net ~]#
Do grupy "production" przynależy 6-hostów (2 z "web_servers", 2 z "db_servers" i 2 z "production"):
[root@vm0-net ~]# ansible -i inventory --list-hosts production
hosts (6):
10.8.232.61
10.8.232.62
web1-net.int.networkers.pl
web2-net.int.networkers.pl
db1-net.int.networkers.pl
db2-net.int.networkers.pl
[root@vm0-net ~]#
Da się także podać kilka plików inwentarzy. Działamy wtedy na zbiorze łącznym. Dotyczy to wszystkich grup.
[root@vm0-net ~]# cat inventory1
[production]
10.8.232.61
10.8.232.62
[root@vm0-net ~]# cat inventory2
[production]
10.8.232.63
10.8.232.64
[root@vm0-net ~]# ansible -i inventory1 -i inventory2 --list-hosts production
hosts (4):
10.8.232.61
10.8.232.62
10.8.232.63
10.8.232.64
[root@vm0-net ~]#
Wróćmy do wspomnianych wcześniej grup wbudowanych: "upgrouped" i "all". Pierwsza zawiera 4 hosty znajdujące się na samej górze naszego pliku inwentarza, w miejscu gdzie definiuje się hosty nieprzynależące do żadnych grup:
[root@vm0-net ~]# ansible -i inventory --list-hosts ungrouped
hosts (4):
vm1-net.int.networkers.pl
vm2-net.int.networkers.pl
10.8.232.123
10.8.232.124
[root@vm0-net ~]#
A druga zawiera wszystkie hosty jakie zostały zdefiniowane w pliku inwentarza:
[root@vm0-net ~]# ansible -i inventory --list-hosts all
hosts (10):
vm1-net.int.networkers.pl
vm2-net.int.networkers.pl
10.8.232.123
10.8.232.124
10.8.232.61
10.8.232.62
web1-net.int.networkers.pl
web2-net.int.networkers.pl
db1-net.int.networkers.pl
db2-net.int.networkers.pl
[root@vm0-net ~]#
Nasz plik można także nieco uprościć, posługując się zapisem zakresu "[START:END]" w nazwie lub adresie hosta:
- 10.8.232.12[0:9] - adresy IPv4 od 10.8.232.120 do 10.8.232.129.
- 10.8.22[4:5].[0:255] - cała podsieć 10.8.224.0/23, czyli adresy IPv4 od 10.8.224.0 do 10.8.225.255.
- 2001:db8:c1sc0::[a:f] - adresy IPv6 od 2001:db8:c1sc0::a do 2001:db8:c1sc0::f.
- web[1:20].networkers.pl - FQDN od web1.networkers.pl, przez web8.networkers.pl do web20.networkers.pl.
- web[01:20].networkers.pl - FQDN od web01.networkers.pl, przez web08.networkers.pl do web20.networkers.pl.
Porównując dwa ostatnie przykłady, warto zwrócić uwagę na drugi, gdzie we wzorcu pozostawiane są wiodące zera.
Uproszczona wersja naszego poprzedniego pliku inwentarza wygląda jak poniżej:
[root@vm0-net ~]# cat inventory
vm[1:2]-net.int.networkers.pl
10.8.232.12[3:4]
[web_servers]
web[1:2]-net.int.networkers.pl
[db_servers]
db[1:2]-net.int.networkers.pl
[production]
10.8.232.6[1:2]
[production:children]
web_servers
db_servers
[db_and_web:children]
web_servers
db_servers
[root@vm0-net ~]#
Weryfikacja jego poprawności została pokazana poniżej:
[root@vm0-net ~]# ansible -i inventory --list-hosts ungrouped
hosts (4):
vm1-net.int.networkers.pl
vm2-net.int.networkers.pl
10.8.232.123
10.8.232.124
[root@vm0-net ~]# ansible -i inventory --list-hosts db_servers
hosts (2):
db1-net.int.networkers.pl
db2-net.int.networkers.pl
[root@vm0-net ~]# ansible --inventory inventory --list-hosts db_and_web
hosts (4):
web1-net.int.networkers.pl
web2-net.int.networkers.pl
db1-net.int.networkers.pl
db2-net.int.networkers.pl
[root@vm0-net ~]#
W pliku inwentarza można także dodawać komentarze. Każda linia komentarza powinna być rozpoczęta znakiem "#".
O ile domyślną lokalizacją pliku inwentarza jest "/etc/ansible/hosts", to w praktyce się go nie używa. Zwykle tworzy się plik w katalogu danego projektu, a następnie wskazuje się go za pomocą opcji "-i", "--inventory" lub ustawienia pliku "ansible.cfg".
Zapraszamy do
Plik konfiguracyjny Ansible
Lokalizację używanego pliku konfiguracyjnego można sprawdzić za pomocą polecenia "ansible --version".
Poniżej widać, że jest to plik "/etc/ansible/ansible.cfg":
[root@vm0-net ~]# ansible --version
ansible [core 2.16.14]
config file = /etc/ansible/ansible.cfg
configured module search path = ['/root/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python3.12/site-packages/ansible
ansible collection location = /root/.ansible/collections:/usr/share/ansible/collections
executable location = /bin/ansible
python version = 3.12.9 (main, Feb 4 2025, 00:00:00) [GCC 14.2.1 20250110 (Red Hat 14.2.1-7)] (/usr/bin/python3)
jinja version = 3.1.5
libyaml = True
[root@vm0-net ~]# cat /etc/redhat-release
Red Hat Enterprise Linux release 10.0 (Coughlan)
[root@vm0-net ~]#
Jest to domyślny plik, którego można nadpisać plikiem "~/.ansible.cfg". Jeżeli potrzebujemy różnej konfiguracji dla każdego z projektów, to da się je nadpisać plikiem "./ansible.cfg" w katalogu, w którym wydawane będzie polecenie "ansible". Istnieje też możliwość skorzystania ze zmiennej "$ANSIBLE_CONFIG". To ostatnie przydaje się, kiedy korzystamy z wielu plików konfiguracyjnych i nie chcemy przemieszczać się pomiędzy różnymi katalogami.
Kolejność wyszukiwania pliku konfiguracyjnego Ansible została zestawiona poniżej:
- "$ANSIBLE_CONFIG"
- "./ansible.cfg"
- "~/.ansible.cfg"
- "/etc/ansible/ansible.cfg"
Zatem, domyślny plik konfiguracji stosowany jest tylko, jeżeli żaden inny nie zostanie znaleziony. Najlepszą praktyką jest stosowanie pliku "./ansible.cfg" w katalogu, z którego uruchamiamy polecenie "ansible".
[msleczek@vm0-net projekt_A]$ pwd
/home/msleczek/projekt_A
[msleczek@vm0-net projekt_A]$ ansible --version | grep "config file"
config file = /etc/ansible/ansible.cfg
[msleczek@vm0-net projekt_A]$ touch ~/.ansible.cfg
[msleczek@vm0-net projekt_A]$ ansible --version | grep "config file"
config file = /home/msleczek/.ansible.cfg
[msleczek@vm0-net projekt_A]$ touch ansible.cfg
[msleczek@vm0-net projekt_A]$ ansible --version | grep "config file"
config file = /home/msleczek/projekt_A/ansible.cfg
[msleczek@vm0-net projekt_A]$ touch /home/msleczek/ansible-projekt_A.cfg
[msleczek@vm0-net projekt_A]$ export ANSIBLE_CONFIG=/home/msleczek/ansible-projekt_A.cfg
[msleczek@vm0-net projekt_A]$ ansible --version | grep "config file"
config file = /home/msleczek/ansible-projekt_A.cfg
[msleczek@vm0-net projekt_A]$ rm /home/msleczek/ansible-projekt_A.cfg
[msleczek@vm0-net projekt_A]$ ansible --version | grep "config file"
config file = /home/msleczek/projekt_A/ansible.cfg
[msleczek@vm0-net projekt_A]$ unset ANSIBLE_CONFIG
[msleczek@vm0-net projekt_A]$
Plik wskazany zmienną "$ANSIBLE_CONFIG" musi istnieć. Jeżeli Ansible go nie znajdzie, to przejdzie do kolejnego miejsca, którym jest "./ansible.cfg". Widać to powyżej, kiedy plik ten usunęliśmy jeszcze przed usunięciem zmiennej "$ANSIBLE_CONFIG".
Warto nadmienić jeszcze jedną bardzo ważną rzecz. Ansible nie załaduje pliku "ansible.cfg" z katalogu bieżącego, jeżeli katalog ten ma uprawnienia do zapisu dla każdego (ang. world-writable). Jest tak ze względów bezpieczeństwa, gdyż inny użytkownik mógł podrzucić tam spreparowany odpowiednio plik. Jeżeli z jakiś powodów musimy korzystać z takiego katalogu, wymagane będzie wskazanie go w zmiennej "$ANSIBLE_CONFIG". Niemniej, dobrze to wcześniej przemyśleć i rozważyć wynikające z tego ryzyko.
Plik konfiguracyjny Ansible zapisany jest w formacie INI. Składa się z sekcji definiowanych nawiasami kwadratowymi "[]", które zawierają ustawienia w formacie "klucz = wartość". Do dwóch najczęściej stosowanych sekcji należy:
- [defaults] - domyślne ustawienia Ansible,
- [privilege_escalation] - definiuje jak Ansible eskaluje uprawnienia na zarządzanych hostach.
W praktyce, plik ten tworzony jest m.in. w celu wskazania inwentarza oraz dostosowania sposobu łączenia się do hostów w ramach danego projektu. Przykładową zawartość pliku "ansible.cfg" w tym zakresie można zobaczyć poniżej:
[msleczek@vm0-net projekt_A]$ cat ansible.cfg
[defaults]
inventory = ./inventory
remote_user = user
ask_pass = false
[privilege_escalation]
become = true
become_method = sudo
become_user = root
become_ask_pass = false
[msleczek@vm0-net projekt_A]$
Nazwy użytych parametrów są na tyle intuicyjne, że wprost wskazują swoje zastosowanie:
- inventory - ścieżka do pliku inwentarza (można nadpisać "-i" lub "--inventory").
- remote_user - nazwa użytkownika, jaka zostanie użyta do logowania (domyślnie bieżący użytkownik).
- ask_pass - czy ma pytać o hasło (jeżeli używamy publicznego klucza do SSH, to powinna być "false").
- become - czy ma automatycznie eskalować uprawnienia (domyślnie "false").
- become_method - metoda wykorzystana do eskalacji uprawnień (domyślnie "sudo").
- become_user - użytkownika do którego odbywa się eskalacja na zarządzanym hoście (domyślnie "root").
- become_ask_pass - czy ma pytać o hasło w trakcie eskalacji (domyślnie "false").
Dzięki odpowiedniej konfiguracji tego pliku nie trzeba podawać wszystkich parametrów, przez co wygodniej się pracuje. Dla przykładu poniżej widać, że nie musimy już wskazywać inwentarzu:
[msleczek@vm0-net projekt_A]$ ansible --list-hosts production
hosts (6):
10.8.232.61
10.8.232.62
web1-net.int.networkers.pl
web2-net.int.networkers.pl
db1-net.int.networkers.pl
db2-net.int.networkers.pl
[msleczek@vm0-net projekt_A]$
Zainteresowanych zakupem lub wdrożeniem Red Hat Ansible Automation Platform zapraszamy do
Stosowanie wzorców dopasowania na inwentarzu
Tak wygląda składnia stosowanego przez nas polecenia do weryfikacji inwentarzu:
$ ansible [pattern] --list-hosts
W miejscu "[pattern]" podawaliśmy do tej pory pojedyncze hosty lub grupy. Natomiast może być to dowolny wzorzec (ang. pattern), który będzie dalej dopasowywany do zdefiniowanych w inwentarzu obiektów. Składać się on może z wielu elementów, które separuje się ":" lub ",". Pojawić się w nim mogą także znaki specjalne, jak "!", "&" czy "*". W takich przypadkach wzorzec należy umieszczać wewnątrz pojedynczego cudzysłowu - 'pattern' - lub poprzedzić te znaki specjalne za pomocą znaku backslash "\". Można też cały wzorzec podawać zawsze w pojedynczym cudzysłowiu - 'pattern' - wtedy będzie to uniwersalne i nie natrafimy na żadne problemy (nawet, jeśli nie zawiera on znaków specjalnych).
Przykłady najczęściej stosowanych wzorców (ang. pattern) dopasowania:
- host1:host2 lub host1,host2 - suma hostów (wiele hostów).
- web_servers:db_servers lub web_servers,db_servers - wszystkie hosty z obu podanych grup.
- production:!db_servers lub production,!db_servers - wszystkie hosty z production, ale bez tych z db_servers.
- production:&db_servers lub production,&db_servers - wszystkie hosty z production, które są w db_servers.
- *networkers.pl - wszystkie obiekty inwentarza posiadające na końcu nazwy "networkers.pl".
- 10.8.232.* - wszystkie obiekty z inwentarza posiadające na początku nazwy "10.8.232.".
Zanim pokażemy działanie tych wzorców, sprawdźmy na jakim inwentarzu pracujemy:
[msleczek@vm0-net projekt_A]$ grep inventory ansible.cfg
inventory = ./inventory3
[msleczek@vm0-net projekt_A]$ cat inventory3
[web_servers]
web1-net.int.networkers.pl
web2-net.int.networkers.pl
[db_servers]
db1-net.int.networkers.pl
db2-net.int.networkers.pl
[dns_servers]
10.8.232.61
10.8.232.62
[east_datacenter]
web1-net.int.networkers.pl
db1-net.int.networkers.pl
10.8.232.61
[west_datacenter]
web2-net.int.networkers.pl
db2-net.int.networkers.pl
10.8.232.62
[production]
web1-net.int.networkers.pl
web2-net.int.networkers.pl
db1-net.int.networkers.pl
db2-net.int.networkers.pl
10.8.232.61
10.8.232.62
[development]
vm1-net.int.networkers.pl
vm2-net.int.networkers.pl
10.8.232.123
10.8.232.124
[msleczek@vm0-net projekt_A]$
Podana lista hostów lub grup we wzorcu nie musi ograniczać się do 2 obiektów:
[msleczek@vm0-net projekt_A]$ ansible 10.8.232.61,db2-net.int.networkers.pl,10.8.232.62 --list-hosts
hosts (3):
10.8.232.61
db2-net.int.networkers.pl
10.8.232.62
[msleczek@vm0-net projekt_A]$
Poniżej zobaczyć można kolejno użycie operatora sumy, różnicy i iloczynu na dwóch zbiorach grup:
[msleczek@vm0-net projekt_A]$ ansible 'production:db_servers' --list-hosts
hosts (6):
web1-net.int.networkers.pl
web2-net.int.networkers.pl
db1-net.int.networkers.pl
db2-net.int.networkers.pl
10.8.232.61
10.8.232.62
[msleczek@vm0-net projekt_A]$ ansible 'production:!db_servers' --list-hosts
hosts (4):
web1-net.int.networkers.pl
web2-net.int.networkers.pl
10.8.232.61
10.8.232.62
[msleczek@vm0-net projekt_A]$ ansible 'production:&db_servers' --list-hosts
hosts (2):
db1-net.int.networkers.pl
db2-net.int.networkers.pl
[msleczek@vm0-net projekt_A]$
Znak '*' umożliwia wygodne dopasowywanie do fragmentów zadanego wzorca. W ten sposób łatwo można odwołać się do hostów pracujących w ramach konkretnej domeny, czy posiadających określone adresy IP. Podawane wzorce muszą pasować do obiektów, jakie znajdują się w inwentarzu. Zatem, jeżeli wszystko podajemy po nazwach, to próba przeszukiwania inwentarza po adresach IP nie powiedzie się i analogicznie w drugą stronę.
Poniżej widać przykład użycia '*' we wzoru z nazwą i adresem IP (należy pamiętać, że jest to znak specjalny):
[msleczek@vm0-net projekt_A]$ ansible \*networkers\* --list-hosts
hosts (6):
web1-net.int.networkers.pl
web2-net.int.networkers.pl
db1-net.int.networkers.pl
db2-net.int.networkers.pl
vm1-net.int.networkers.pl
vm2-net.int.networkers.pl
[msleczek@vm0-net projekt_A]$ ansible '*networkers*' --list-hosts
hosts (6):
web1-net.int.networkers.pl
web2-net.int.networkers.pl
db1-net.int.networkers.pl
db2-net.int.networkers.pl
vm1-net.int.networkers.pl
vm2-net.int.networkers.pl
[msleczek@vm0-net projekt_A]$ ansible '10.8.232.6*': --list-hosts
hosts (2):
10.8.232.61
10.8.232.62
[msleczek@vm0-net projekt_A]$
Otrzymane wcześniej wyniki można dalej wygodnie zawężać, tworząc bardziej rozbudowane wzorce:
[msleczek@vm0-net projekt_A]$ ansible '10.8.232.6*:&east_datacenter' --list-hosts
hosts (1):
10.8.232.61
[msleczek@vm0-net projekt_A]$
Niektóre z bardziej złożonych wzorców mogą być dość użyteczne. Dla przykładu możemy chcieć wykonać operacje na wszystkich serwerach webowych i baz danych, które pracują w środowisku produkcyjnym, ale nie są ulokowane w zachodnim centrum danych:
[msleczek@vm0-net projekt_A]$ ansible 'web_servers:db_servers:&production:!west_datacenter' --list-hosts
hosts (2):
web1-net.int.networkers.pl
db1-net.int.networkers.pl
[msleczek@vm0-net projekt_A]$
Dla bardziej wymagających, w ramach wzorca dostępne są też zaawansowane wyrażenia regularne. Aby z nich korzystać, należy poprzedzić wzorzec znakiem '~'. W takim wzorcu będzie stosowane wiele znaków specjalnych, dlatego najlepiej od razu wprowadzać go w pojedynczych znakach cudzysłowiu.
[msleczek@vm0-net projekt_A]$ ansible '~10.8.232.6[12]' --list-hosts
hosts (2):
10.8.232.61
10.8.232.62
[msleczek@vm0-net projekt_A]$ ansible '~(web|db)_*' --list-hosts
hosts (4):
web1-net.int.networkers.pl
web2-net.int.networkers.pl
db1-net.int.networkers.pl
db2-net.int.networkers.pl
[msleczek@vm0-net projekt_A]$
Ciekawa jest też możliwość odwoływania się do hostów po numerze ich pozycji w ramach zadanej grupy. Do tego celu korzysta się z nawiasów kwadratowych "[]". W ten sposób można zarówno wskazać numer pozycji "[POZYCJA]", jak i zakres "[START:END]". Numery pozycji w ramach grupy zaczynają się od zera.
[msleczek@vm0-net projekt_A]$ ansible 'production' --list-hosts
hosts (6):
web1-net.int.networkers.pl
web2-net.int.networkers.pl
db1-net.int.networkers.pl
db2-net.int.networkers.pl
10.8.232.61
10.8.232.62
[msleczek@vm0-net projekt_A]$ ansible 'production[0]' --list-hosts
hosts (1):
web1-net.int.networkers.pl
[msleczek@vm0-net projekt_A]$ ansible 'production[1]' --list-hosts
hosts (1):
web2-net.int.networkers.pl
[msleczek@vm0-net projekt_A]$ ansible 'production[-1]' --list-hosts
hosts (1):
10.8.232.62
[msleczek@vm0-net projekt_A]$ ansible 'production[2:]' --list-hosts
hosts (4):
db1-net.int.networkers.pl
db2-net.int.networkers.pl
10.8.232.61
10.8.232.62
[msleczek@vm0-net projekt_A]$ ansible 'production[2:3]' --list-hosts
hosts (2):
db1-net.int.networkers.pl
db2-net.int.networkers.pl
[msleczek@vm0-net projekt_A]$
Opanowanie zasad korzystania z inwentarza oraz pliku konfiguracji Ansible jest niezbędną podstawą do dalszej pracy. Braki w tym obszarze będą ciągnęły się za nami przez cały czas, dlatego zalecamy poświęcenie odpowiedniej ilości czasu temu zagadnieniu przed przejściem do kolejnych artykułów.
Zapraszamy do
Przed kolejną porcją wiedzy zachęcamy do przećwiczenia i utrwalenia tej poznanej tutaj. Skorzystaj z naszych ćwiczeń!